Enseña a tu BME688 a oler

Una guía completa sobre cómo entrenar su sensor BME688
¡Hola amigos entusiastas de la tecnología! Bosch ha lanzado el BME688Un nuevo e impresionante sensor que puede distinguir hasta cuatro olores diferentes. Esta guía explicará todos los detalles para enseñar a tu BME688 a distinguir olores. No te preocupes si eres nuevo en la IA o en Python. Esta guía es adecuada para principiantes.
Así que, vamos a saltar a la derecha.
Requisitos previos
- Raspberry Pi
- Placa de interconexión BME688 o Kit de desarrollo del sensor de gas BME688 de Bosch
- Especímenes que producen los olores deseados
- Un recipiente hermético para alojar el sensor y la muestra
- BSEC y AI Studio de Bosch
- PiCockpit
Pasos
- Elija su aplicación
- Registrar datos
- Entrenar el algoritmo
- Detectar olores
1. Elija su aplicación
El primer paso es elegir su aplicación. Para esta guía voy a utilizar la carne y el queso como ejemplos. Pero hay un abanico infinito de posibilidades. Puedes distinguir las frutas de las verduras o los productos de limpieza de los perfumes. También se puede intentar determinar cuándo la comida se ha estropeado.
Hay ciertas cosas que debe tener en cuenta a la hora de elegir una aplicación. Necesitas muchos ejemplares para cada clase que quieras distinguir, para asegurarte de que el algoritmo sea robusto. Para empezar, debe elegir algo que sea barato y esté ampliamente disponible. También hay que tener en cuenta que es aconsejable utilizar el aire normal como una de las clases, ya que casi siempre estará presente.
Para crear un algoritmo robusto debe utilizar al menos media hora de datos de medición para cada espécimen. Por lo tanto, los especímenes que producen un olor constante son una buena elección. Asegúrese también de utilizar una amplia gama de especímenes. Si, por ejemplo, sólo utiliza naranjas, limones y limas para su clase de fruta, el sensor podría no clasificar una frambuesa como fruta, porque es demasiado diferente de los especímenes que utilizó para el entrenamiento. Cuanto más especímenes diferentes se utilicen, mejor.
Una vez que hayas finalizado tu elección, es el momento de crear un nuevo proyecto de AI Studio. Abre AI Studio y pulsa el botón Crear un proyecto ... Botón. Pulse Configurar la placa BME si desea registrar datos con una configuración específica.
2. Registrar los datos
Este proceso varía, dependiendo de si se utiliza el Placa de interconexión BME688 o Kit de desarrollo del sensor de gas BME688 de Bosch (más placa lanzadera). La placa shuttle es más fácil de usar y capturará los datos ocho veces más rápido que la placa breakout, pero es mucho más cara. En las siguientes secciones explicaré en detalle ambos métodos.
Nota: El sensor BME688 necesita algo de tiempo para adaptarse al entorno y quemarse. Asegúrate de dejarlo funcionando durante al menos 24 horas antes de registrar los datos de tu entrenamiento
Grabación de datos con la tarjeta BME688 Shuttle Board
BOSCH equipó la placa de la lanzadera con ocho sensores BME688, por lo que produce ocho veces más datos en el mismo tiempo. Todo el software está ya instalado y está listo para salir de la caja. Ver este video tutorial de Bosch para conocer el proceso de medición.
Si grabas muchos especímenes en una sola sesión, es posible que quieras anotar la secuencia de los especímenes para evitar confusiones. Siempre puedes recortar los datos en AI Studio más tarde, así que no tengas miedo de capturar muchos datos.
Registro de datos con la placa de circuito impreso BME688
Si está utilizando el Placa de interconexión BME688 Aún así te aconsejo que veas el Tutorial de Bosch porque proporciona información útil sobre el proceso de entrenamiento en AI Studio. Pero para registrar los datos de entrenamiento se requieren algunos pasos adicionales.
Nosotros, en pi3g ha creado una biblioteca de python para los sensores BME68X, que se puede actualizar con Bosch BSEC 2.0. Por lo tanto, es útil si tienes algo de experiencia en python, pero no es necesario.
Nota: Consulte las instrucciones de instalación y uso directamente en nuestro GitHub.
Comience por clonar nuestro bme68x-python-library. Esto puede hacerse ejecutando el siguiente comando en un terminal bash.
git clone https://github.com/pi3g/bme68x-python-library.gitAhora necesitas construir e instalar el módulo python bme68x. El BSEC 2.0 es un software propietario, por lo que debes descargar la versión 2.0.6.1 directamente de Bosch y aceptar su licencia. Descomprímelo en la carpeta bme68x-python-library y procede con estos comandos.
cd path/to/bme68x-python-library
sudo python3 setup.py installAhora puede ejecutar el bmerawdata.py con la configuración por defecto.
cd tools/bmerawdata
python3 bmerawdata.pyEl script mostrará los datos registrados después de cada medición. Finalice el script y guarde los datos en un archivo compatible con AI Studio pulsando Ctrl+c.
3. Entrenar el algoritmo
Importar datos
Independientemente de si se utiliza el Placa de interconexión BME688 o el Kit de desarrollo del sensor de gas BME688 de BoschEl siguiente paso es importar los datos a AI Studio. Pulse el botón Importar datos y seleccione su archivo .bmerawdata.
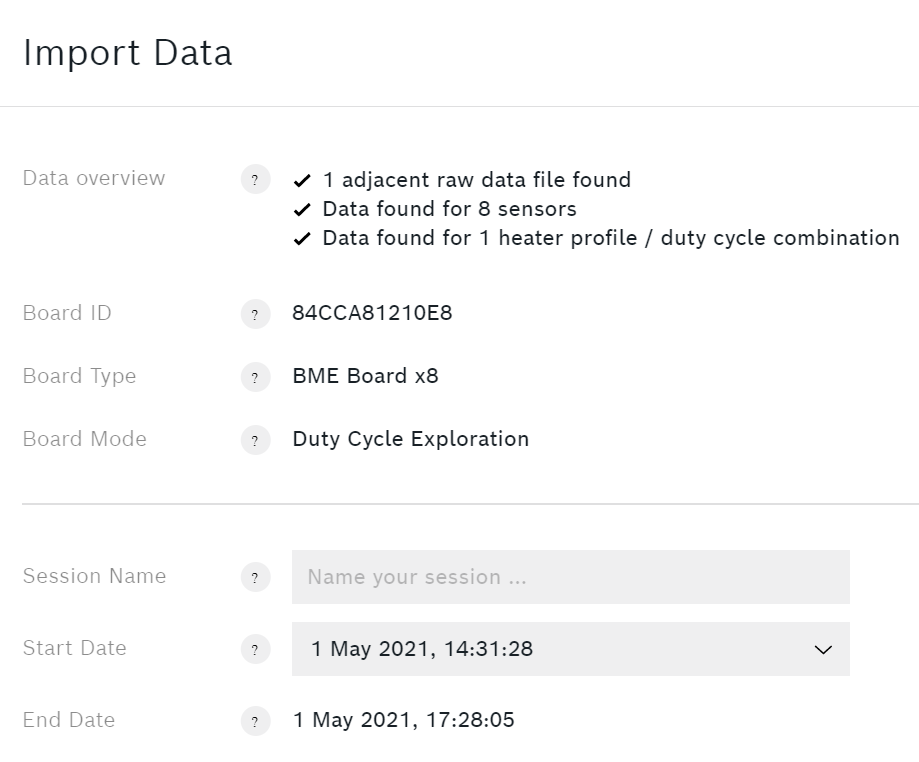
Su sesión necesita un nombre significativo. Es conveniente elegir una enumeración de los ejemplares.
Puede ver un gráfico de sus datos, por ejemplo del canal de datos de gas, como se muestra a continuación.
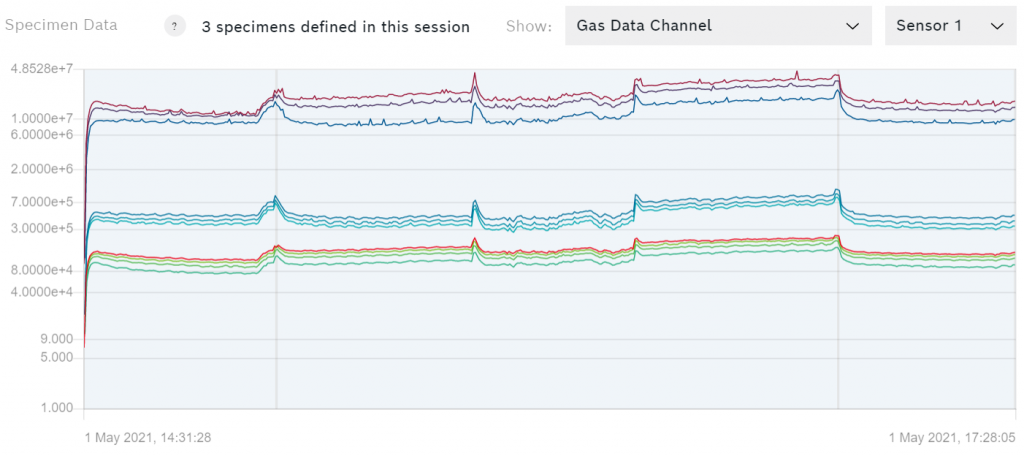
Si los datos proceden de la placa del transbordador, se puede alternar entre los datos de los ocho sensores. Cada una de las líneas de color representa un paso del perfil del calentador que se utilizó para capturar los datos.
Nota: En la mayoría de los casos, sólo debe utilizar el canal de datos de gas para el entrenamiento.
Ahora tenemos que etiquetar nuestros especímenes. Si grabaste los datos con la placa de lanzadera y utilizaste los botones de a bordo para marcar los especímenes, ya podrás ver una plantilla para cada uno de ellos. También puedes recortar los especímenes y crear otros nuevos (por ejemplo, si grabaste varios especímenes con la placa de la lanzadera).
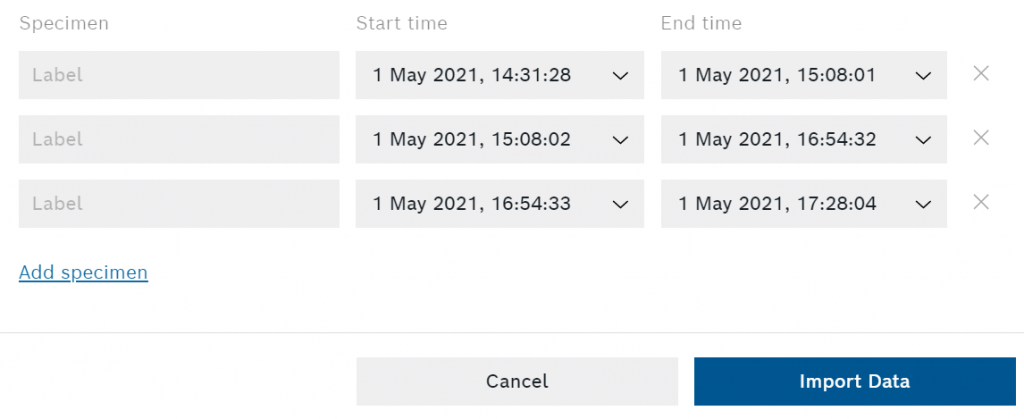
Cuando haya terminado de editar la sesión, pulse la tecla Importar datos en la esquina inferior derecha del diálogo.
Una vez importados y etiquetados todos los especímenes, es el momento de crear y entrenar el algoritmo.
Crear el algoritmo
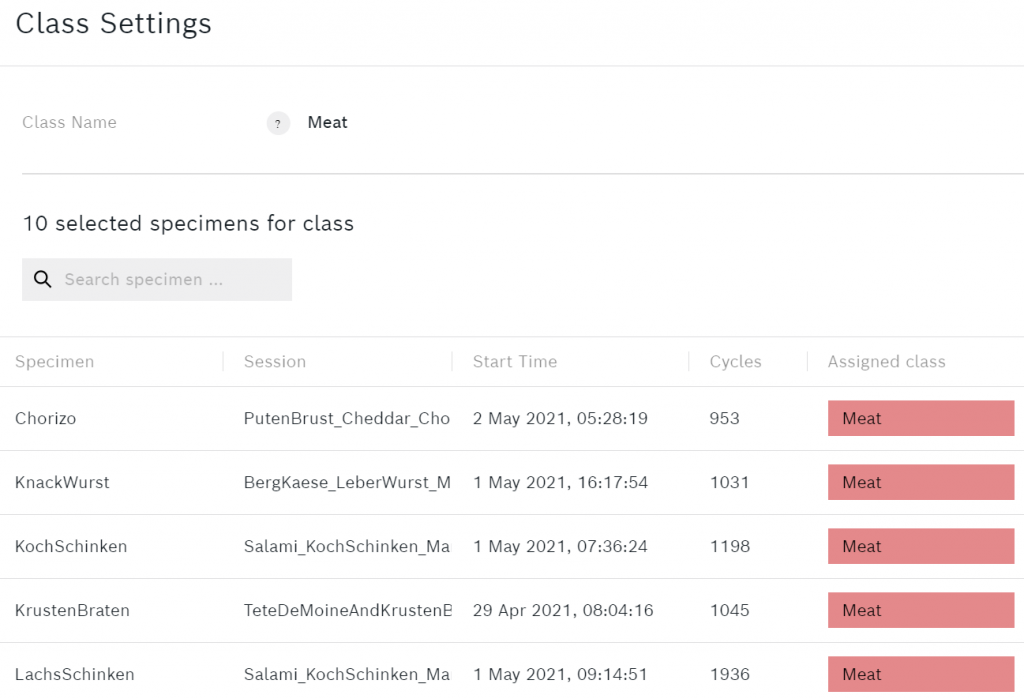
Seleccione Mis algoritmos en la parte superior y haga clic en + Nuevo Algoritmo . Dale a tu algoritmo un nombre que represente lo que se supone que debe hacer, en mi caso AirMeatCheese. A continuación, añadir las clases. Yo he llamado a mis clases AireNormal, Carne y Queso. Seleccione qué especímenes pertenecen a cada clase y elija un color para cada clase.

Para añadir o eliminar especímenes puede hacer clic en una de las clases. Este es un ejemplo de lo que el Carne clase parece.
Debajo de las clases puedes ver algunos datos adicionales sobre el algoritmo.
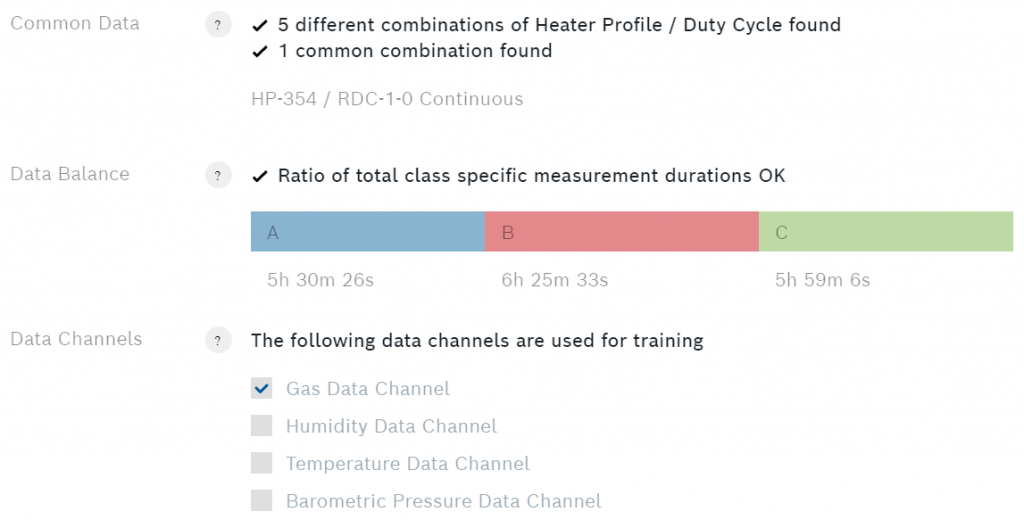
El balance de datos muestra la duración total de la medición de cada clase. Para garantizar el mejor rendimiento, la duración de la medición de cada clase debe ser igual. Si la duración de la medición de una de las clases es mucho mayor, podría experimentar un sesgo del algoritmo hacia esa clase. Observe también el botón de signo de interrogación que se encuentra delante de cada epígrafe. Púlselo para obtener información más detallada.
Nota: Asegúrate de consultar la documentación de BME688 AI Studio para obtener más información.
En los canales de datos puede seleccionar cuál de las cuatro salidas de los sensores quiere utilizar para su algoritmo. Recomiendo utilizar sólo el canal de datos de gas, ya que los otros canales dependen principalmente del entorno y no del espécimen. Una vez que hayas configurado todo, es el momento de entrenar.
Formación y exportación
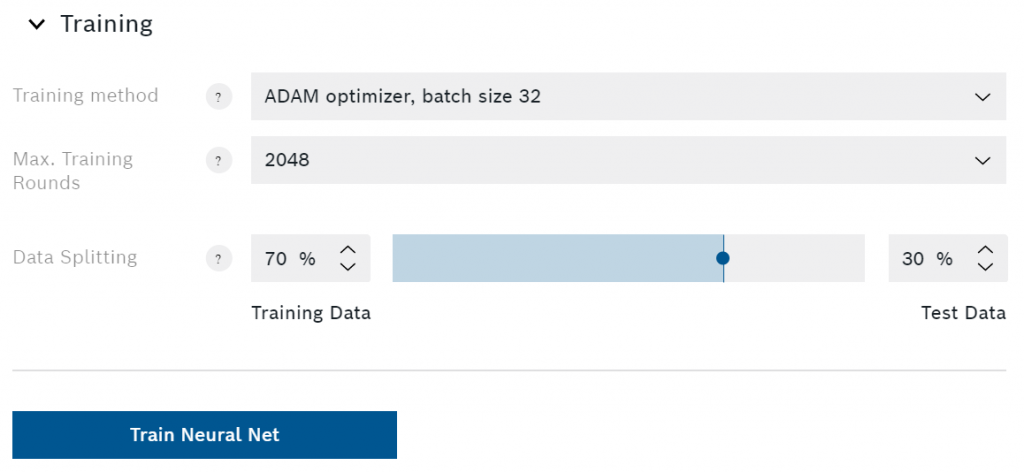
Aquí puede seleccionar el método de entrenamiento, las rondas máximas y la división de datos. Si eres nuevo en el mundo de las redes neuronales, deberías dejar todo en la configuración por defecto. No obstante, intentaré explicar brevemente cada uno de esos ajustes.
El único método de entrenamiento disponible en el momento en que escribo esto es el optimizador ADAM. Se trata de una forma específica de encontrar un mínimo en la función de error (menos error significa predicciones más precisas). Se pueden seleccionar diferentes tamaños de lote para mejorar la velocidad y la estabilidad del entrenamiento.
Aumentar el número máximo de rondas de entrenamiento es otra forma de mejorar el rendimiento del algoritmo. En cada ronda (a menudo denominada época), AI Studio alimenta todo el conjunto de datos de entrenamiento a través de la red neuronal. Esto significa que un mayor número de rondas máximas aumentará el tiempo de entrenamiento del algoritmo. La mayoría de las veces, AI Studio detectará si se alcanza un mínimo y terminará el entrenamiento antes de que se alcancen las rondas máximas. Esto reduce el tiempo de entrenamiento y evita el sobreajuste.
La sobreadaptación significa que la red neuronal se ha ajustado demasiado a los datos de entrenamiento. Si el algoritmo obtiene una precisión muy alta en el entrenamiento, pero su rendimiento es pobre en las pruebas de la vida real, es posible que desee disminuir las rondas máximas de entrenamiento.
La configuración de la división de los datos le permite seleccionar qué parte de los datos registrados se utiliza para el entrenamiento y qué parte se utiliza para la prueba. Debe evitar utilizar más de un tercio de los datos para las pruebas. Como su nombre indica, el algoritmo sólo utilizará los datos de entrenamiento para la formación. Una vez finalizado el entrenamiento, AI Studio evaluará el algoritmo utilizando los datos de prueba, que nunca ha visto antes.
Pulse Entrenar la red neuronal para iniciar el entrenamiento. Verá el tiempo de entrenamiento restante estimado y el gráfico de líneas de la precisión y la pérdida.
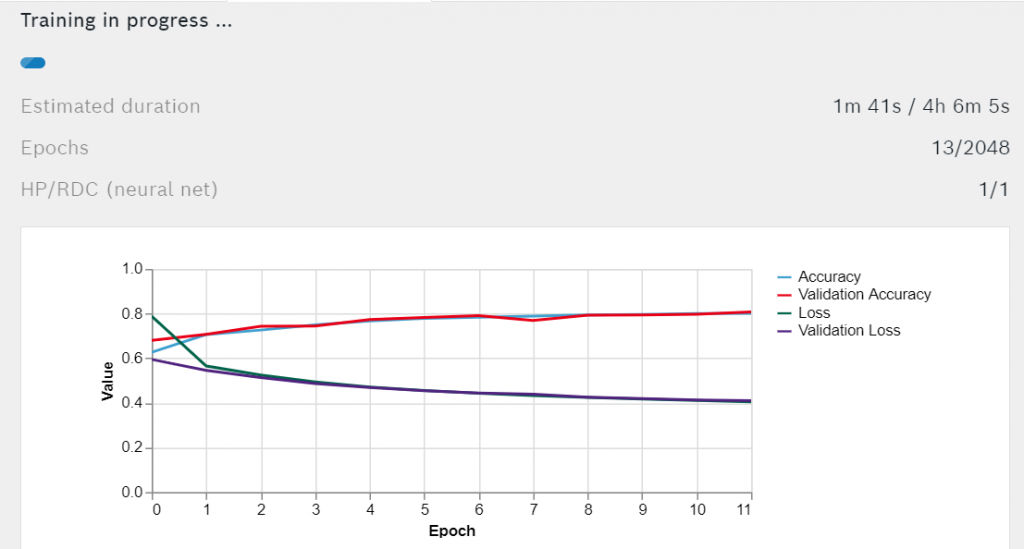
Con cada epoch la Precisión y la Precisión de Validación deberían mejorar, mientras que la Pérdida y la Pérdida de Validación deberían disminuir. Espere a que termine el entrenamiento.
Una vez terminado el entrenamiento, compruebe la matriz de confusión. Contiene información importante sobre los resultados del entrenamiento. La estadística más interesante es la precisión, pero si los datos de entrenamiento están distribuidos de forma desigual, la puntuación F1 podría ser una métrica mejor.
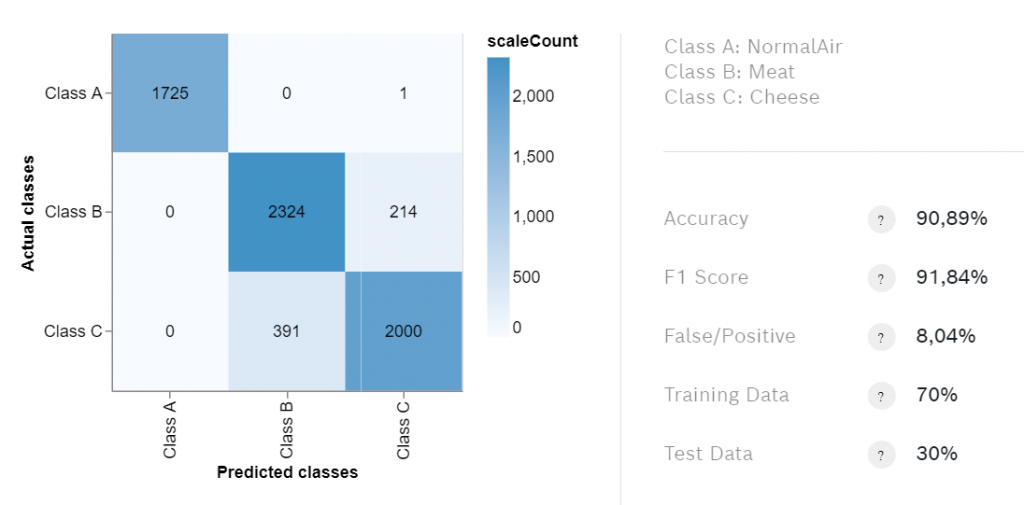
Rara vez se conseguirá una precisión superior a 90%, por lo que si la precisión es superior a 80% se debe exportar el algoritmo para probarlo. Detectaremos los olores utilizando nuestro PiCockpit interfaz web. Asegúrese de exportar el algoritmo para la versión 2.0.6.1 de BSEC ya que PiCockpit sólo es compatible con esta versión hasta ahora.
Nota: En la mayoría de los casos, la formación terminará antes de alcanzar la duración estimada.
4. Detectar olores
Para detectar los olores basta con instalar el PiCockpit y conéctalo a tu cuenta. Si no tiene PiCockpit pero sólo tienes que registrarte gratuitamente y seguir las instrucciones que allí se indican. Nuestra aplicación Digital Nose le permite cargar su algoritmo entrenado y ver las predicciones en vivo a través de la interfaz web. Consulte la Ayuda para la nariz digital para obtener una explicación completa sobre el uso de la aplicación.
Otra forma de detectar los olores es utilizando nuestro BME68X Extensión Python. Esto requiere algo de codificación en python, pero ofrece más control y le permite crear sus propias aplicaciones utilizando su algoritmo. Consulte el README.mdEl Documentación.md y el ejemplos para aprender a instalar y utilizar la extensión.
Así que ahí lo tienes. Ahora debería ser capaz de registrar datos, entrenar su algoritmo y detectar olores. Por favor, hazme saber si has encontrado esta guía útil o si has experimentado algún problema al seguir esta guía.
Póngase en contacto conmigo en [email protected]
Para mí, el entrenamiento del algoritmo no funciona. En su lugar, el software muestra el error "El algoritmo no pudo ser entrenado. Parece que faltan datos de entrenamiento o de prueba". Sin embargo, he capturado alrededor de una hora de datos para cada una de mis clases utilizando la placa de ruptura BME688. ¿Tienes alguna idea de lo que podría estar haciendo mal?
Parece que el archivo .bmerawdata podría estar dañado. Podrías intentar echar un vistazo al archivo, para ver si hay algún valor malo contenido. Está en formato json
¿has encontrado una solución para esto?
Hola Nathan
También acabo de probar tu código y me da el mismo error al hacer un algoritmo.
" Parece que faltan datos de entrenamiento o de prueba".
¿hay algún problema en su código maby?
Hola Thomas
Todavía no he podido recrear el error.
¿Qué versión de AI Studio utilizas? El script fue probado con la versión 1.6.0 de AI Studio
Hola Nathan
He utilizado la versión más reciente (1.6.0) y te he enviado un correo electrónico al respecto, ¿quieres que te envíe los archivos de muestra?
He intentado muchas pruebas pero el mismo error cada vez 🙁
Sí, también estoy usando la versión 1.6.0. Por favor, compruebe estos archivos de recogida de datos, uno de ellos es el de los humos y el otro es el del aire normal. https://we.tl/t-PwfkYXjnGP
[...] encendido, como un sensor de temperatura y humedad o quizás un proyecto de calidad del aire con un DHT22 o un BME688, o un sensor de luminosidad con un [...]
[...] Enseña a tu BME688 a oler [...]