BME688に匂いを教える

BME688センサーのトレーニング方法を徹底解説
技術愛好家の皆さん、こんにちは。ボッシュがリリースした BME688BME688には、最大4種類の香りを識別できる新しいセンサーが搭載されています。このガイドでは、BME688に匂いを識別する方法を教えるためのすべての詳細を説明します。AIやPythonに慣れていない方もご安心ください。このガイドは、初心者向けです。
では、早速ですが、ご紹介します。
前提条件
- Raspberry Pi
- BME688ブレイクアウトボード または ボッシュ BME688 ガスセンサーデベロッパーキット
- 欲しい香りがする試料
- センサーと試料を入れる密閉容器
- BSECとAI Studio by Bosch
- PiCockpit
ステップ
- アプリケーションの選択
- 記録データ
- アルゴリズムの学習
- 匂いの検出
1.アプリケーションの選択
最初のステップは、アプリケーションを選択することです。このガイドでは、肉とチーズを例に挙げています。しかし、可能性は無限にあります。果物と野菜を区別したり、洗浄剤と香水を区別したりすることができます。また、食べ物が腐っているかどうかを判断することもできます。
アプリケーションを選ぶ際に考慮すべき点があります。アルゴリズムの堅牢性を確保するためには、識別したいクラスごとに多くの標本が必要です。まず、安価で広く入手できるものを選ぶべきです。また、クラスの1つとして通常の空気を使用することをお勧めします。なぜなら、通常の空気はほとんど常に存在するからです。
ロバストなアルゴリズムを作成するためには、各標本について少なくとも30分程度の測定データを使用する必要があります。そのためには、一定の香りを発する試料が良いでしょう。また、さまざまな種類の標本を使用するようにしてください。例えば、果物の分類にオレンジ、レモン、ライムしか使わなかった場合、センサーはラズベリーを果物として分類できない可能性があります。これは、学習に使った標本とはあまりにも違いすぎるからです。より多くの異なる標本を使用することが望ましいのです。
選択肢を確定したら、新しいAI Studioプロジェクトを作成しましょう。AI Studioを開いて プロジェクトの作成 ... ボタンです。押す BMEボードの設定 特定の設定でデータを記録したい場合は
2.データの記録
を使用するかどうかで、このプロセスは異なります。 BME688ブレイクアウトボード または ボッシュ BME688 ガスセンサーデベロッパーキット (さらにシャトルボード)を購入しました。シャトルボードの方が使いやすく、ブレイクアウトボードの8倍の速さでデータを取り込むことができますが、価格はかなり高くなります。以下、両方の方法を詳しく説明します。
注意してください。 BME688センサーは、環境への適応と焼き付けに時間が必要です。トレーニングデータを記録する前に、最低でも24時間は稼働させておいてください
BME688 Shuttle Boardによるデータの記録
BOSCHはこのシャトルボードにBME688センサーを8個搭載しているため、同じ時間で8倍のデータを得ることができます。ソフトウェアはすべてインストールされているので、箱から出してすぐに使うことができます。見る ボッシュのこのビデオチュートリアル をクリックすると、測定プロセスについての説明が表示されます。
1回のセッションで多くの標本を記録する場合は、混乱を避けるために、標本の順番をメモしておくとよいでしょう。あとでAI Studioでデータをトリミングすることができますので、たくさんのデータを撮影することを恐れないでください。
BME688ブレイクアウトボードによるデータの記録
を使用している場合は BME688ブレイクアウトボード を見ることを今でも勧めています。 ボッシュ・チュートリアル なぜなら、AI Studioのトレーニングプロセスに関する有益な情報が得られるからです。しかし、トレーニングデータを記録するためには、いくつかの追加手順が必要です。
私たちは pi3g BME68Xセンサー用のpythonライブラリを作成し、以下の方法でアップグレードすることができます。 ボッシュのBSEC 2.0.そのため、Pythonの経験があると便利ですが、必須ではありません。
注意してください。 インストールや使用方法については、直接、当社の GitHub.
のクローンを作ることから始めましょう。 bme68x-python-library.これは、bash端末で以下のコマンドを実行することで実現できます。
git clone https://github.com/pi3g/bme68x-python-library.gitここでは、bme68xパイソンモジュールをビルドしてインストールする必要があります。そのためには BSEC 2.0 2.0.6.1をボッシュから直接ダウンロードし、ライセンスに同意する必要があります。bme68x-python-library」フォルダに解凍し、以下のコマンドを実行してください。
cd path/to/bme68x-python-library
sudo python3 setup.py installを実行できるようになりました。 bmerawdata.py スクリプトをデフォルトの設定で作成します。
cd tools/bmerawdata
python3 bmerawdata.pyスクリプトは、測定ごとに記録されたデータを表示します。スクリプトを終了し、データをAI Studio互換ファイルに保存するには Ctrl+c.
3.アルゴリズムの学習
インポートデータ
を使っているかどうかにかかわらず BME688ブレイクアウトボード またはその ボッシュ BME688 ガスセンサーデベロッパーキットをクリックすると、次のステップとしてAI Studioにデータをインポートすることができます。を押します。 インポートデータ ボタンをクリックして、.bmerawdataファイルを選択します。
あなたのセッションには意味のある名前が必要です。標本の列挙を選択するのが適しています。
下図のように、ガスのデータチャンネルの例では、データのプロットが表示されます。
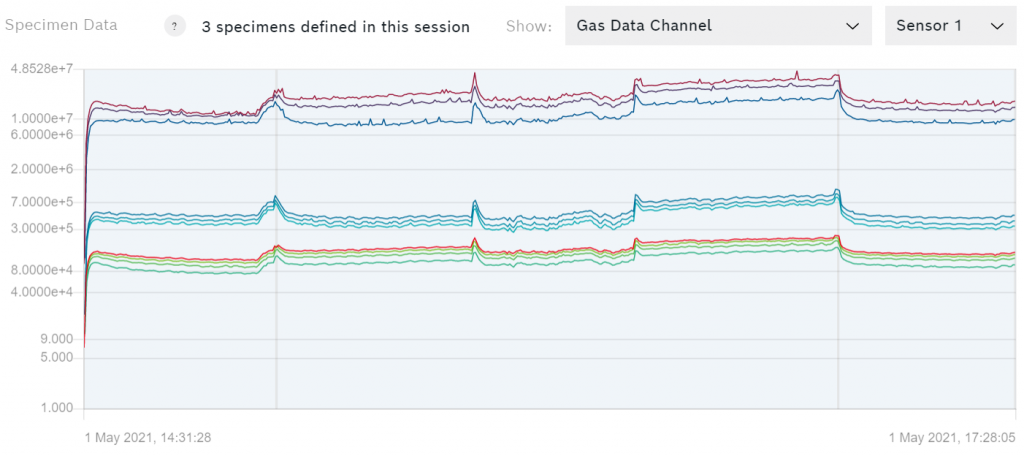
シャトルボードからのデータの場合は、8つのセンサーのデータを切り替えることができます。色のついた線は、データを取得するために使用されたヒータープロファイルの1ステップを表しています。
注意してください。 ほとんどの場合、トレーニングにはガスデータチャネルのみを使用する必要があります。
今度は、標本にラベルを付ける必要があります。シャトルボードを使ってデータを記録し、オンボードのボタンを使って標本をマークした場合は、すでにそれぞれの標本にテンプレートが表示されています。また、標本をトリミングしたり、新しい標本を作成することもできます(例えば、弊社のブレイクアウトボードを使って複数の標本を記録した場合など)。
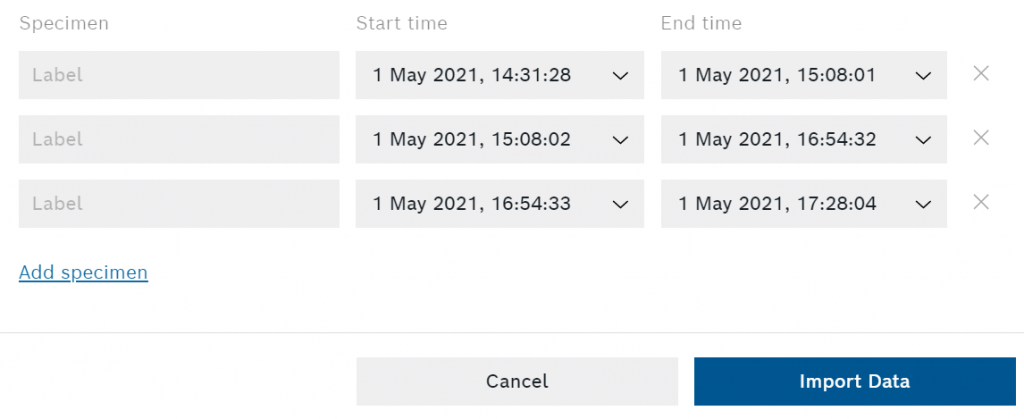
セッションの編集が終わったら インポートデータ ダイアログの右下にあるボタンをクリックします。
すべての標本をインポートしてラベルを付けたら、アルゴリズムの作成と学習を行います。
アルゴリズムの作成
セレクト 私のアルゴリズム をクリックしてください。 + 新アルゴリズム .あなたのアルゴリズムに、それが何をすることになっているかを表す名前を付けてください。 AirMeatCheese.そして、クラスを追加します。私はクラスを「NormalAir」「Meat」「Cheese」と名付けました。どの標本がどのクラスに属するかを選択し、各クラスの色を選択します。

標本を追加・削除するには、いずれかのクラスをクリックします。以下は、その例です。 肉 クラスは次のようになります。
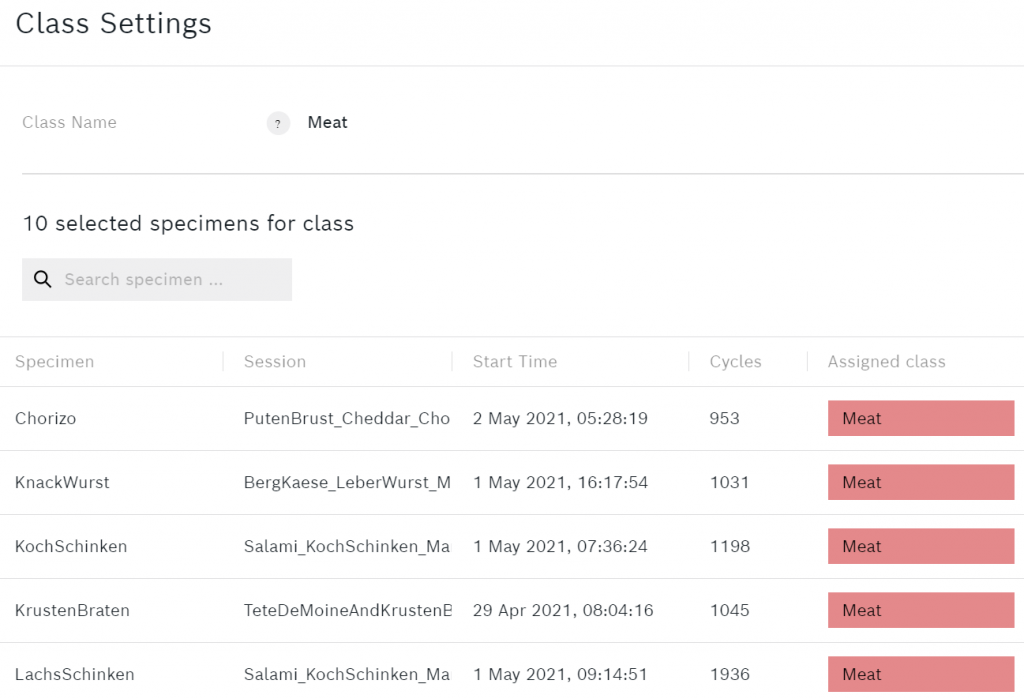
クラスの下には、アルゴリズムに関する追加データが表示されています。
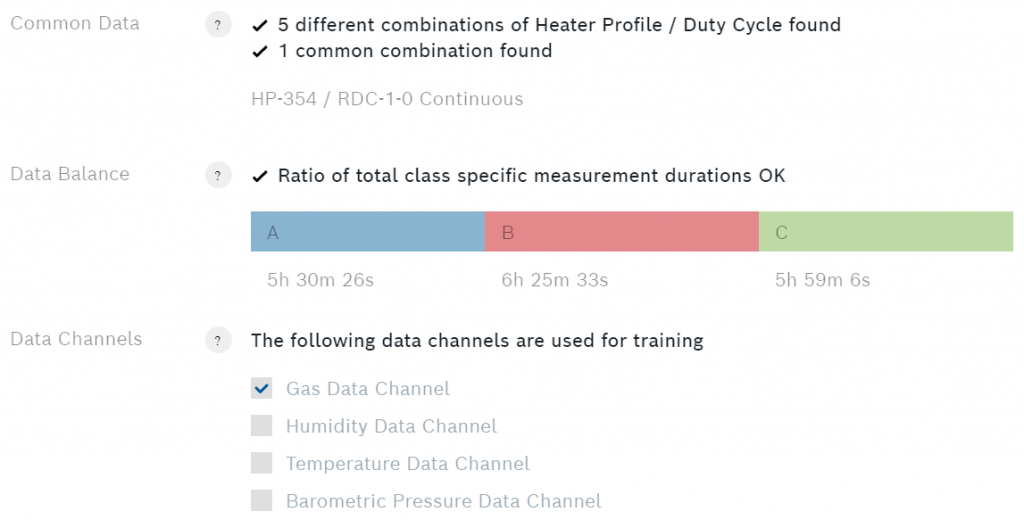
データバランスは、各クラスの合計測定時間を示しています。最良のパフォーマンスを得るためには、各クラスの測定期間が等しいことが必要です。いずれかのクラスの測定時間がはるかに大きい場合、そのクラスにアルゴリズムのバイアスがかかる可能性があります。また、各見出しの前にあるクエスチョンマークのボタンにも注目してください。これを押すと、より詳細な情報を得ることができます。
注意してください。 詳細については、BME688 AI Studioのドキュメントをご確認ください。
データチャンネルでは、4つのセンサー出力のうち、アルゴリズムに使用するものを選択できます。他のチャンネルは、検体ではなく環境に依存することが多いので、ガスデータチャンネルのみを使用することをお勧めします。すべての設定が完了したら、いよいよトレーニングです。
トレーニングと輸出
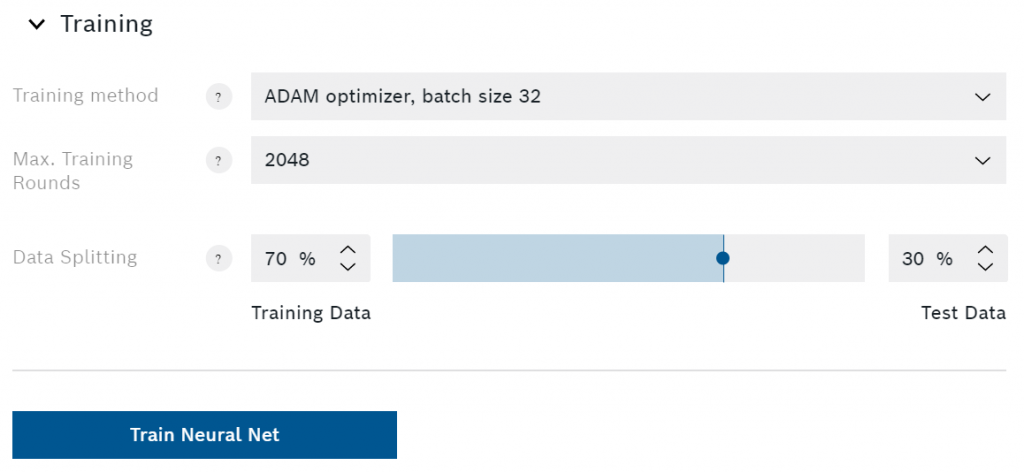
ここでは、学習方法、最大ラウンド数、データ分割を選択できます。ニューラルネットワークに慣れていない方は、すべてデフォルトの設定のままにしておいたほうがいいでしょう。とはいえ、それぞれの設定を簡単に説明してみます。
私がこれを書いている時点で利用可能な唯一のトレーニング方法は、ADAMオプティマイザーです。これは、誤差関数の最小値を見つける特殊な方法です(誤差が少ないほど、より正確な予測が可能になります)。学習速度と安定性を向上させるために、異なるバッチサイズを選択することができます。
最大トレーニングラウンド数を増やすことも、アルゴリズムの性能を向上させる方法です。AI Studioは、各ラウンド(エポックと呼ばれることもあります)ごとに、トレーニングデータセット全体をニューラルネットワークに送り込みます。つまり、最大ラウンド数が多いほど、アルゴリズムの学習にかかる時間が長くなります。ほとんどの場合、AI Studioは最小値に達したことを検知し、最大ラウンド数に達する前にトレーニングを終了します。これにより、学習時間が短縮され、オーバーフィッティングを防ぐことができます。
オーバーフィッティングとは、ニューラルネットワークがトレーニングデータに合わせて調整しすぎたことを意味します。トレーニングでは非常に高い精度を示しているのに、実際のテストではパフォーマンスが低い場合は、最大トレーニングラウンド数を減らした方がよいでしょう。
データ分割の設定では、記録したデータのうち、どれだけをトレーニングに使用し、どれだけをテストに使用するかを選択できます。テストにデータの3分の1以上を使用することは避けるべきです。その名の通り、アルゴリズムはトレーニング用のデータのみを使用して学習を行います。トレーニングが終了すると、AI Studioはこれまで見たことのないテストデータを使ってアルゴリズムを評価します。
プレス ニューラルネットの学習 をクリックしてトレーニングを開始します。トレーニングの残り時間の目安や、精度と損失の折れ線グラフが表示されます。
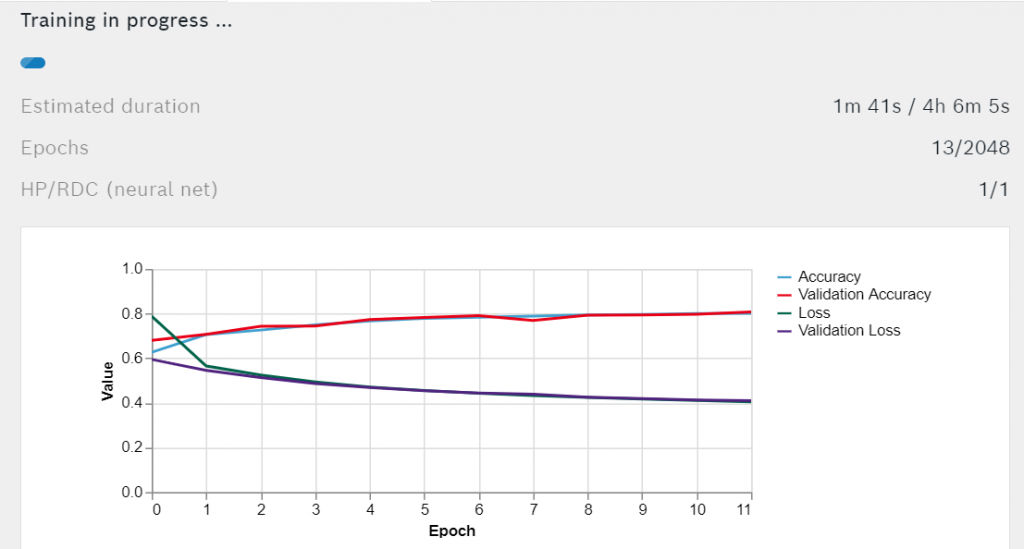
エポック毎に、AccuracyとValidation Accuracyは向上し、LossとValidation Lossは減少するはずです。トレーニングが終了するまで待ちます。
トレーニングが終了したら、混同行列を確認します。トレーニングの結果に関する重要な情報が含まれています。最も興味深い統計は精度ですが、トレーニングデータが不均等に分布している場合は、F1スコアの方が良い指標になるかもしれません。
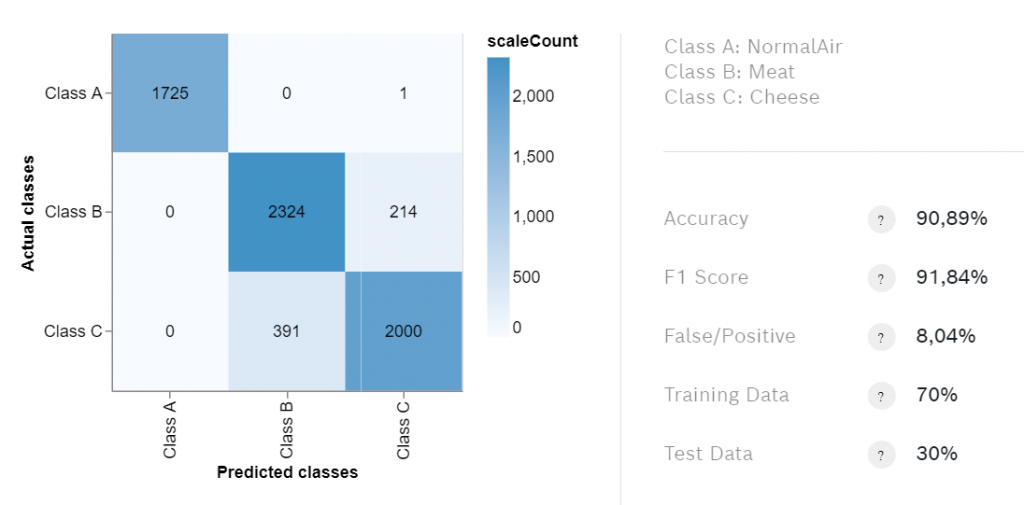
90%以上の精度が出ることはほとんどないので、80%以上の精度の場合はアルゴリズムをエクスポートしてテストする必要があります。匂いの検出には PiCockpit ウェブ・インターフェースBSECバージョン2.0.6.1のアルゴリズムをエクスポートするようにしてください。 PiCockpit は、今のところこのバージョンにしか対応していません。
注意してください。 ほとんどの場合、推定期間に達する前にトレーニングが終了します。
4.においの検出
をインストールするだけで、匂いを検出することができます。 PiCockpit クライアントを使用して、自分のアカウントに接続します。を持っていない場合は PiCockpit デジタルノーズのアプリは、無料で登録でき、その指示に従うだけです。Digital Noseアプリでは、あなたの学習したアルゴリズムをアップロードして、ウェブインターフェースでライブ予測を見ることができます。をご覧ください。 デジタルノーズヘルプ をクリックすると、アプリの使い方の詳細が表示されます。
また、匂いを検出する方法としては、当社の BME68X パイソンエクステンション.これにはPythonでのコーディングが必要ですが、コントロール性が高く、自分のアルゴリズムを使った独自のアプリケーションを作ることができます。を参照してください。 README.mdを使用しています。 ドキュメント.md とのことです。 例 フォルダーをご覧になり、拡張機能のインストールと使用方法をご確認ください。
さて、これで完成です。これで、データの記録、アルゴリズムの学習、ニオイの検出ができるようになります。このガイドが役に立ったかどうか、あるいはこのガイドに沿って何か問題が発生したかどうか、私に教えてください。
[email protected] までご連絡ください。
私の場合、アルゴリズムのトレーニングがうまくいきません。代わりに「Algorithm could not be trained」というエラーが表示されます。トレーニングデータかテストデータのどちらかが不足しているようです "と表示されます。しかし、BME688 Breakout Boardを使用して、各クラスで約1時間のデータを取得しました。何が間違っているのでしょうか?
.bmerawdataファイルが破損している可能性があるようです。そのファイルを見て、何か悪い値が含まれていないか確認してみてください。これはjson形式です。
この問題の解決策は見つかったのでしょうか?
こんにちは、ネイサン
私もあなたのコードを試したところ、アルゴリズムを作成する際に同じエラーが発生しました。
"トレーニングデータまたはテストデータのいずれかが欠落しているようです。"
は、あなたのコードに何か問題があるのでしょうか?
トーマス
まだエラーの再現はできていません。
AI Studio dpのバージョンは?AI Studioバージョン1.6.0にて動作確認済みです。
こんにちは、ネイサン
最新版(1.6.0)を使いましたので、サンプルファイルをお送りしましょうか?
いろいろと試してみましたが、毎回同じエラーです。
はい、私も1.6.0を使用しています。データ収集のファイルを確認してください。 https://we.tl/t-PwfkYXjnGP
[DHT22やBME688を使用した温度・湿度センサーや空気品質プロジェクト、あるいはライトセンサーを使用した明るさセンサーなどです。
[...] BME688に匂いを教えよう [...]