Insegna al tuo BME688 come annusare

Una guida completa su come addestrare il tuo sensore BME688
Ciao amici appassionati di tecnologia! Bosch ha rilasciato il BME688, un nuovo fantastico sensore che può distinguere fino a quattro diversi odori. Questa guida vi spiegherà tutti i dettagli per insegnare al vostro BME688 come distinguere gli odori. Non preoccupatevi se siete nuovi di AI o di Python. Questa guida è adatta ai principianti.
Quindi, facciamo un salto avanti.
Prerequisiti
- Raspberry Pi
- Scheda di breakout BME688 o Kit di sviluppo del sensore di gas Bosch BME688
- Esemplari che producono gli odori desiderati
- Un contenitore ermetico per ospitare il sensore e il campione
- BSEC e AI Studio di Bosch
- PiCockpit
Passi
- Scegli la tua applicazione
- Registrare i dati
- Addestrare l'algoritmo
- Rilevare gli odori
1. Scegli la tua applicazione
Il primo passo è quello di scegliere la vostra applicazione. Per questa guida userò carne e formaggio come esempi. Ma c'è una gamma infinita di possibilità. Puoi distinguere la frutta dalla verdura o i detergenti dal profumo. Potresti anche provare a determinare quando il cibo è andato a male.
Ci sono alcune cose che dovreste considerare quando scegliete un'applicazione. Avete bisogno di molti esemplari per ogni classe che volete distinguere, per assicurarvi che l'algoritmo diventi robusto. Per iniziare dovreste scegliere qualcosa che sia economico e ampiamente disponibile. Tenete anche presente che è consigliabile usare l'aria normale come una delle classi, poiché sarà quasi sempre presente.
Per creare un algoritmo robusto si dovrebbe usare almeno mezz'ora di dati di misurazione per ogni esemplare. Pertanto, gli esemplari che producono un profumo costante sono una buona scelta. Assicurati anche di usare una vasta gamma di campioni. Se, per esempio, usi solo arance, limoni e lime per la tua classe di frutta, il sensore potrebbe non riuscire a classificare un lampone come frutta, perché è troppo diverso dagli esemplari che hai usato per l'addestramento. Più esemplari diversi vengono utilizzati, meglio è.
Una volta che avete finalizzato la vostra scelta, è il momento di creare un nuovo progetto AI Studio. Aprite AI Studio e premete il tasto Creare il progetto ... Pulsante. Premere Configurare la scheda BME se volete registrare i dati con una configurazione specifica.
2. Registrare i dati
Questo processo varia, a seconda che si utilizzi l'opzione Scheda di breakout BME688 o Kit di sviluppo del sensore di gas Bosch BME688 (ulteriore scheda shuttle). La scheda shuttle è più facile da usare e catturerà i dati otto volte più velocemente della scheda breakout, ma è molto più costosa. Spiegherò entrambi i metodi in dettaglio nelle sezioni seguenti.
Nota: Il sensore BME688 ha bisogno di un po' di tempo per adattarsi all'ambiente e al rodaggio. Assicurati di lasciarlo in funzione per almeno 24 ore prima di registrare i tuoi dati di allenamento
Registrare dati con la scheda navetta BME688
BOSCH ha equipaggiato la scheda shuttle con otto sensori BME688, quindi produce otto volte più dati nella stessa quantità di tempo. Tutto il software è già installato, ed è pronto a partire dalla scatola. Guarda questo video tutorial di Bosch per conoscere il processo di misurazione.
Se stai registrando molti esemplari in una singola sessione potresti voler annotare la sequenza degli esemplari per evitare confusione. Puoi sempre ritagliare i dati in AI Studio in seguito, quindi non aver paura di catturare molti dati.
Registrare dati con la scheda di breakout BME688
Se state usando il Scheda di breakout BME688 Vi consiglio ancora di guardare il Tutorial Bosch perché fornisce alcune informazioni utili sul processo di formazione in AI Studio. Ma per registrare i dati di allenamento sono necessari alcuni passi aggiuntivi.
Noi di pi3g ha creato una libreria python per i sensori BME68X, che potete aggiornare con Boschs BSEC 2.0. Quindi è utile se avete un po' di esperienza con python, ma non è necessario.
Nota: Vedere le istruzioni per l'installazione e l'uso direttamente sul nostro GitHub.
Iniziare clonando il nostro bme68x-libreria python. Questo può essere fatto eseguendo il seguente comando in un terminale bash.
git clone https://github.com/pi3g/bme68x-python-library.gitOra è necessario costruire e installare il modulo python bme68x. Il BSEC 2.0 è un software proprietario quindi dovete scaricare la versione 2.0.6.1 direttamente da Bosch e accettare la loro licenza. Scompattalo nella cartella bme68x-python-library e procedi con questi comandi.
cd path/to/bme68x-python-library
sudo python3 setup.py installOra potete eseguire il bmerawdata.py con le impostazioni predefinite.
cd tools/bmerawdata
python3 bmerawdata.pyLo script visualizzerà i dati registrati dopo ogni misurazione. Terminare lo script e salvare i dati in un file compatibile con AI Studio premendo Ctrl+c.
3. Addestrare l'algoritmo
Importazione di dati
Indipendentemente dal fatto che stiate usando il Scheda di breakout BME688 o il Kit di sviluppo del sensore di gas Bosch BME688Il passo successivo è importare i dati in AI Studio. Premete il tasto Importazione di dati e seleziona il tuo file .bmerawdata.
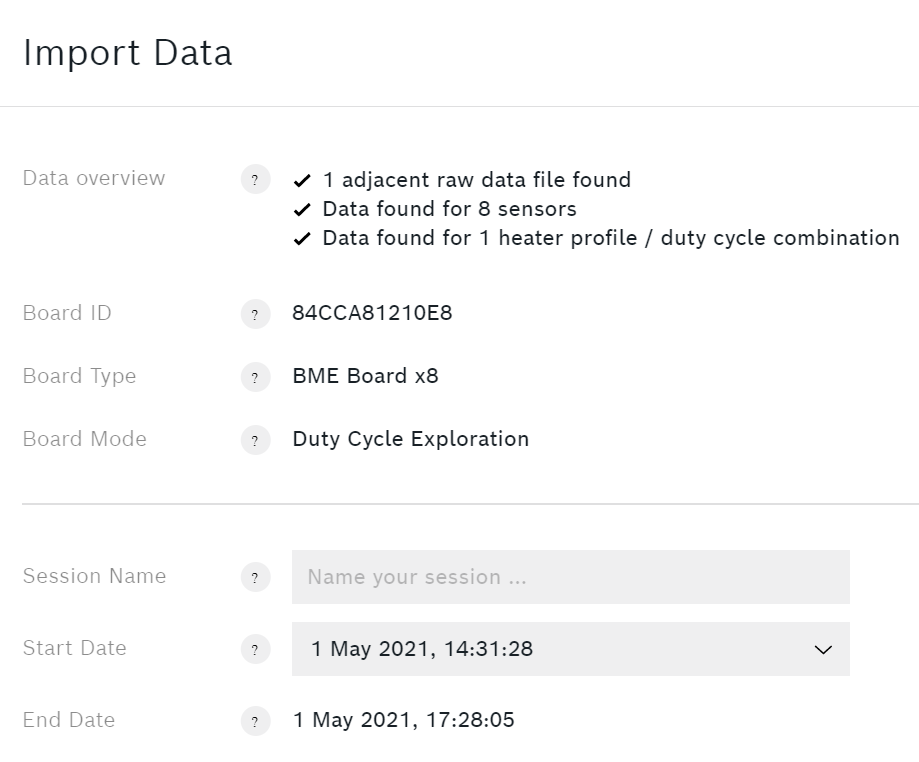
La vostra sessione ha bisogno di un nome significativo. È opportuno scegliere un'enumerazione degli esemplari.
Puoi vedere un grafico dei tuoi dati per esempio del canale dei dati del gas come mostrato qui sotto.
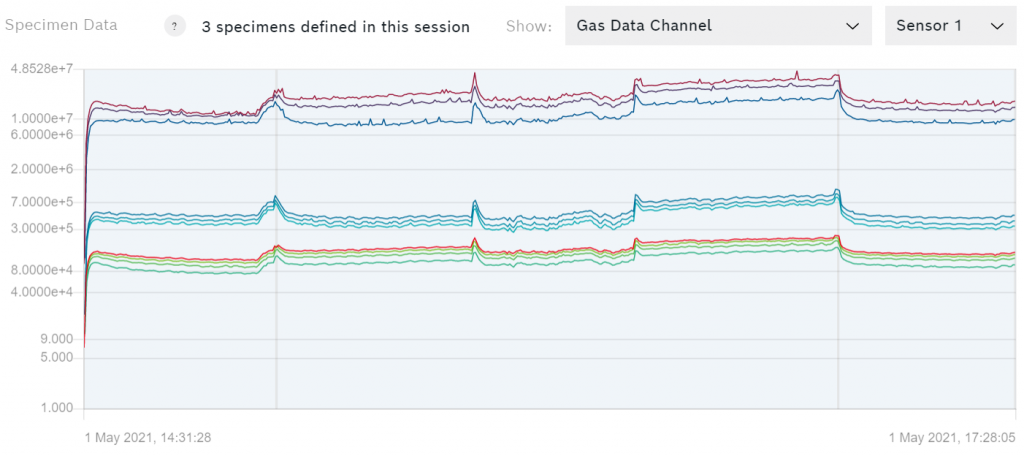
Se i dati provengono dalla scheda shuttle, è possibile passare tra i dati degli otto sensori. Ognuna delle linee colorate rappresenta un passo del profilo del riscaldatore che è stato utilizzato per catturare i dati.
Nota: Nella maggior parte dei casi si dovrebbe usare solo il canale dei dati del gas per l'allenamento.
Ora abbiamo bisogno di etichettare i nostri campioni. Se hai registrato i dati con la scheda di breakout e hai usato i pulsanti a bordo per marcare i campioni, potrai già vedere un modello per ognuno di essi. Puoi anche ritagliare gli esemplari e crearne di nuovi (per esempio se hai registrato più esemplari usando la nostra scheda di breakout).
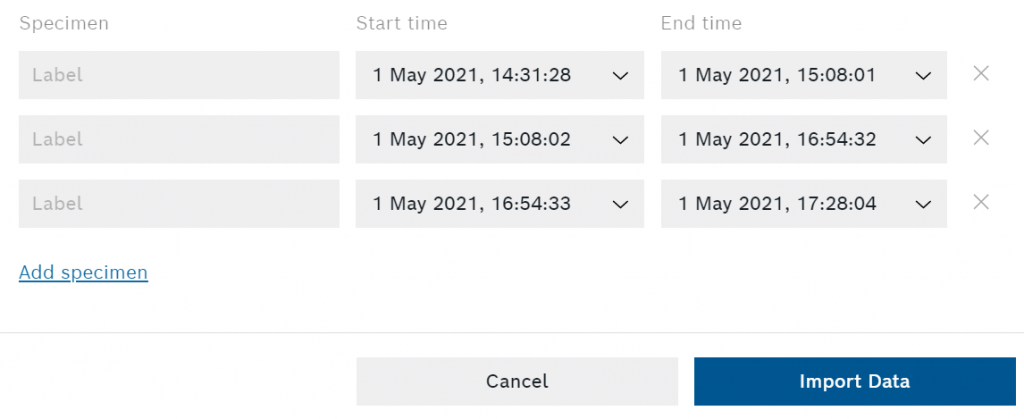
Dopo aver finito di modificare la sessione, premere il tasto Importazione di dati nell'angolo in basso a destra della finestra di dialogo.
Una volta importati ed etichettati tutti i vostri campioni, è il momento di creare e addestrare l'algoritmo.
Creare l'algoritmo
Seleziona I miei algoritmi in alto e cliccare su + Nuovo algoritmo . Date al vostro algoritmo un nome che rappresenti ciò che dovrebbe fare, nel mio caso AirMeatCheese. Poi aggiungete le classi. Ho chiamato le mie classi NormalAir, Meat e Cheese. Seleziona quali esemplari appartengono a quale classe e scegli un colore per ogni classe.
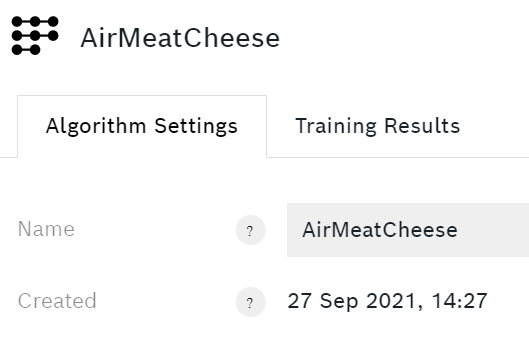

Per aggiungere o rimuovere esemplari puoi cliccare su una delle classi. Ecco un esempio di ciò che il Carne classe assomiglia.
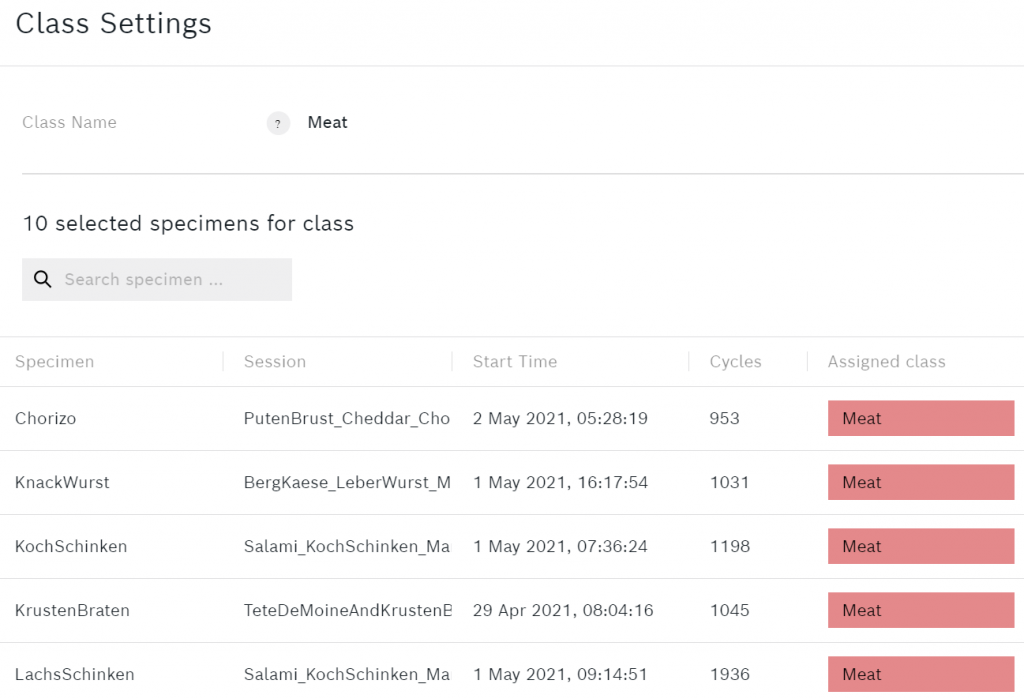
Sotto le classi si possono vedere alcuni dati aggiuntivi sull'algoritmo.
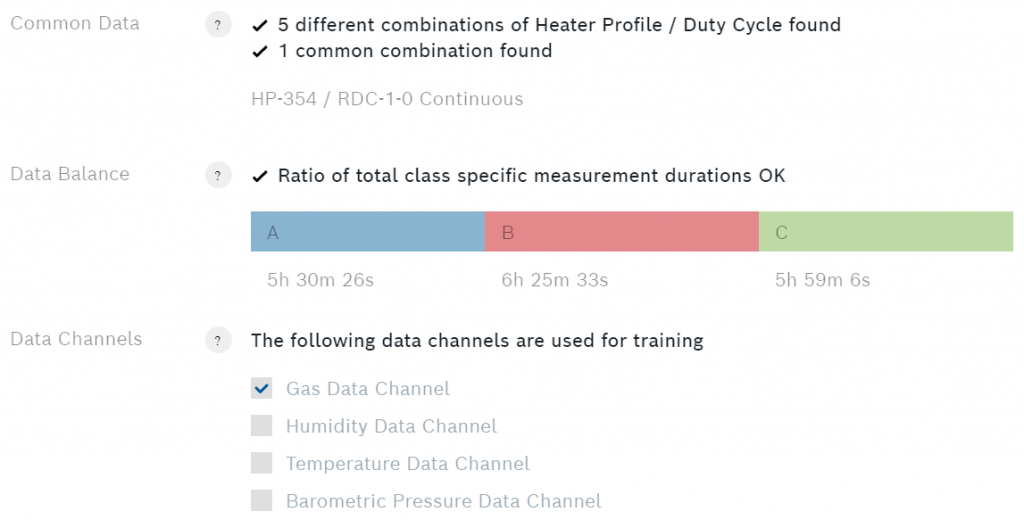
Il bilancio dei dati mostra la durata totale della misurazione per ogni classe. Per garantire le migliori prestazioni, la durata della misurazione di ogni classe dovrebbe essere uguale. Se la durata di misurazione di una delle classi è molto maggiore, si potrebbe verificare una distorsione dell'algoritmo verso quella classe. Nota anche il pulsante con il punto interrogativo di fronte ad ogni voce. Premilo per ottenere informazioni più dettagliate.
Nota: Assicuratevi di controllare la documentazione di BME688 AI Studio per ulteriori informazioni.
Sotto canali di dati potete selezionare quale delle quattro uscite del sensore volete usare per il vostro algoritmo. Raccomando di usare solo il canale dei dati del gas, poiché gli altri canali dipendono principalmente dall'ambiente e non dal campione. Una volta che hai impostato tutto, è il momento dell'allenamento.
Formazione ed esportazione
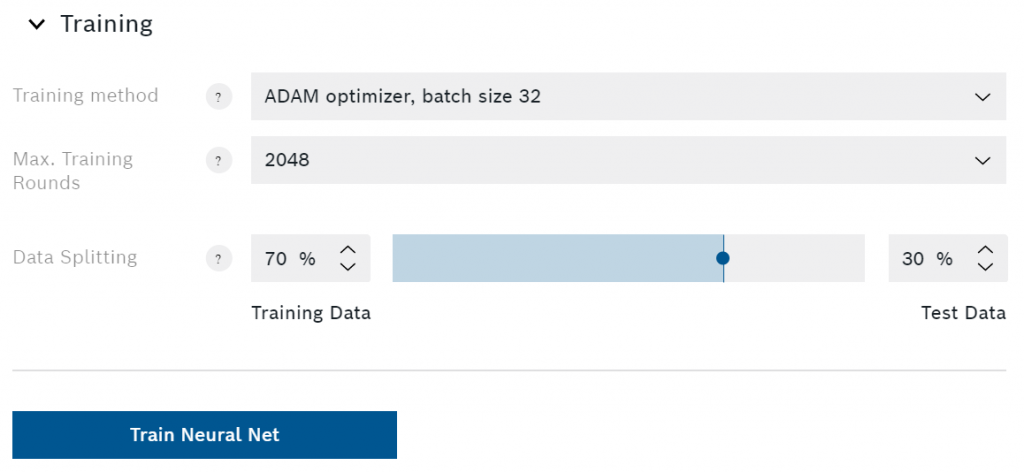
Qui potete selezionare il metodo di addestramento, i giri massimi e la divisione dei dati. Se siete nuovi alle reti neurali, dovreste lasciare tutto alle impostazioni di default. Tuttavia, cercherò di spiegare brevemente ciascuna di queste impostazioni.
L'unico metodo di addestramento disponibile al momento in cui sto scrivendo questo è l'ottimizzatore ADAM. Questo è un modo specifico di trovare un minimo nella funzione di errore (meno errore significa previsioni più accurate). È possibile selezionare diverse dimensioni dei lotti per migliorare la velocità e la stabilità dell'addestramento.
Aumentare il numero massimo di cicli di allenamento è un altro modo per migliorare le prestazioni dell'algoritmo. Per ogni round (spesso indicato come epoch) AI Studio alimenta l'intero set di dati di allenamento attraverso la rete neurale. Ciò significa che un numero maggiore di cicli massimi aumenterà il tempo necessario per addestrare l'algoritmo. La maggior parte delle volte AI Studio rileverà se viene raggiunto un minimo e finirà l'addestramento prima che vengano raggiunti i giri massimi. Questo riduce il tempo di addestramento ed evita l'overfitting.
Overfitting significa che la rete neurale si è adattata troppo ai dati di allenamento. Se l'algoritmo ottiene un'accuratezza molto alta nell'addestramento ma si comporta male nei test della vita reale, si potrebbe voler diminuire i giri massimi di addestramento.
L'impostazione di divisione dei dati ti permette di selezionare quanti dei tuoi dati registrati sono usati per l'addestramento e quanti sono usati per i test. Si dovrebbe evitare di usare più di un terzo dei dati per i test. Come suggerisce il nome, l'algoritmo userà solo i dati di allenamento per la formazione. Dopo che l'addestramento è finito AI Studio valuterà l'algoritmo usando i dati di test, che non ha mai visto prima.
Premere Addestrare la rete neurale per iniziare l'allenamento. Vedrai il tempo di allenamento rimanente stimato e il grafico a linee della precisione e della perdita.
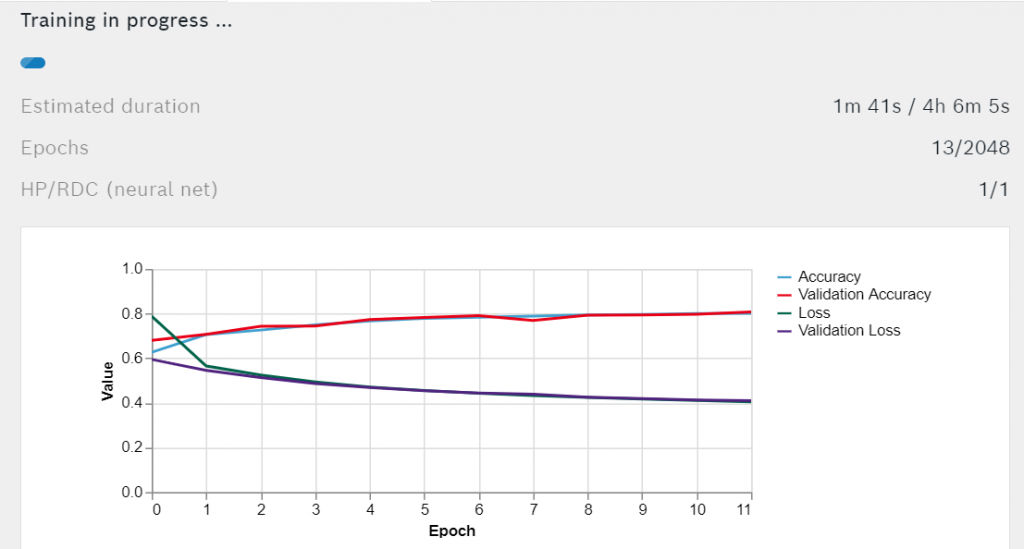
Con ogni epoca la precisione e la precisione di convalida dovrebbero migliorare, mentre la perdita e la perdita di convalida dovrebbero diminuire. Aspettate che l'addestramento sia finito.
Quando l'addestramento è finito, controlla la matrice di confusione. Contiene informazioni importanti sui risultati dell'addestramento. La statistica più interessante è l'accuratezza, ma se i tuoi dati di allenamento sono distribuiti in modo non uniforme, il punteggio F1 potrebbe essere una metrica migliore.
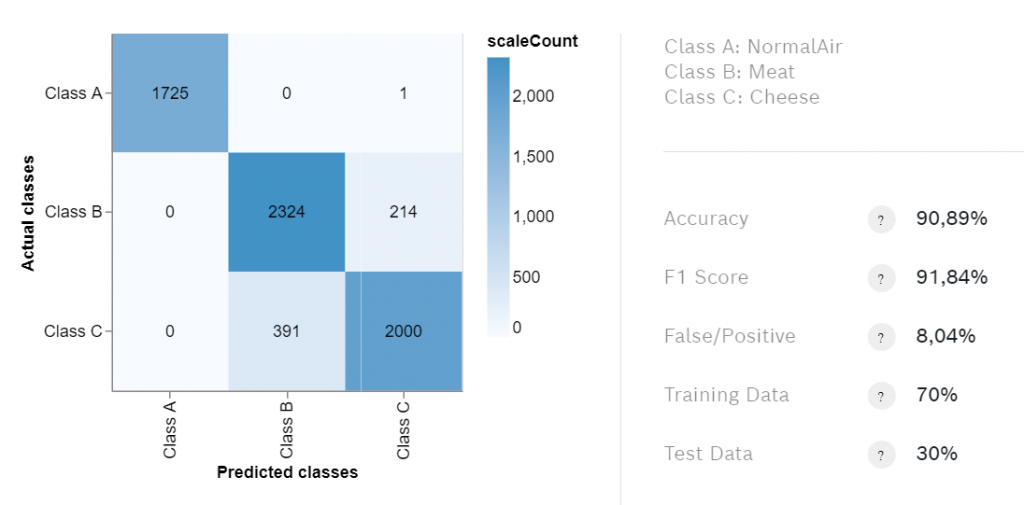
Raramente otterrai una precisione superiore a 90%, quindi se la precisione è superiore a 80% dovresti esportare l'algoritmo per testarlo. Rileveremo gli odori usando il nostro PiCockpit interfaccia web. Assicurati di esportare l'algoritmo per BSEC versione 2.0.6.1 poiché PiCockpit supporta solo questa versione finora.
Nota: Nella maggior parte dei casi l'addestramento sarà finito prima di raggiungere la durata stimata.
4. Rilevare gli odori
Per rilevare gli odori basta installare il programma PiCockpit e collegarlo al tuo account. Se non hai PiCockpit ma basta registrarsi gratuitamente e seguire le istruzioni fornite. La nostra App Naso Digitale ti permette di caricare il tuo algoritmo addestrato e vedere le previsioni dal vivo tramite l'interfaccia web. Controlla il Aiuto per il naso digitale per una spiegazione completa su come utilizzare l'applicazione.
Un altro modo per rilevare gli odori è usare il nostro BME68X estensione Python. Questo richiede un po' di codifica python, ma offre più controllo e vi permette di creare le vostre applicazioni usando il vostro algoritmo. Fate riferimento al README.md, il Documentazione.md e il esempi per imparare a installare e utilizzare l'estensione.
Quindi ecco fatto. Ora dovresti essere in grado di registrare i dati, addestrare il tuo algoritmo e rilevare gli odori. Fammi sapere se hai trovato questa guida utile o se hai avuto qualche problema mentre la seguivi.
Contattatemi a [email protected]
Per me, l'addestramento dell'algoritmo non funziona. Invece, il software mostra l'errore "Algoritmo non può essere addestrato. Sembra che manchino i dati di allenamento o i dati di test". Tuttavia, ho catturato circa un'ora di dati per ciascuna delle mie classi utilizzando la BME688 Breakout Board. Avete qualche idea di cosa potrei fare di sbagliato?
Sembra che il file .bmerawdata possa essere corrotto. Potresti provare a dare un'occhiata al file, per vedere se ci sono dei valori errati contenuti. È in formato json
Hai trovato una soluzione per questo?
Ciao Nathan
Ho anche appena provato il tuo codice e sto ottenendo lo stesso errore quando faccio un algoritmo.
" Sembra che manchino i dati di allenamento o i dati di test".
C'è qualche problema nel tuo codice?
Ciao Thomas
Non sono ancora riuscito a ricreare l'errore.
Che versione di AI Studio dp usi? Lo script è stato testato con AI Studio versione 1.6.0
Ciao Nathan
Ho usato la versione più recente (1.6.0) e ti ho anche inviato una mail su di essa, quindi vuoi che ti mandi i file di esempio?
Ho provato un sacco di test ma lo stesso errore ogni volta 🙁
Sì, anch'io sto usando la 1.6.0, controlla questi file dalla raccolta dati, uno è il fumo, l'altro è l'aria normale https://we.tl/t-PwfkYXjnGP
[...], come un sensore di temperatura e umidità o magari un progetto di qualità dell'aria con un DHT22 o un BME688, o un sensore di luminosità con un [...]
[...] Insegnate al vostro BME688 a sentire gli odori [...]