Leer uw BME688 hoe te ruiken

Een complete gids over hoe uw BME688 sensor te trainen
Hallo mede tech enthousiastelingen! Bosch heeft de BME688, een geweldige nieuwe sensor die tot vier verschillende geuren kan onderscheiden. Deze gids zal alle details uitleggen om je BME688 te leren hoe je geuren moet onderscheiden. Maak je geen zorgen als je nieuw bent in AI of Python. Deze gids is geschikt voor beginners.
Dus, laten we meteen verder gaan.
Vereisten
- Raspberry Pi
- BME688 Breakout Raad of Bosch BME688 gassensor-ontwikkelaarkit
- Specimens die de gewenste geuren produceren
- Een luchtdichte houder voor de sensor en het monster
- BSEC en AI Studio door Bosch
- PiCockpit
Stappen
- Kies uw toepassing
- Gegevens opnemen
- Het algoritme trainen
- Geuren opsporen
1. Kies uw toepassing
De eerste stap is het kiezen van uw toepassing. Voor deze gids gebruik ik vlees en kaas als voorbeeld. Maar er is een eindeloze reeks mogelijkheden. Je kunt fruit van groente onderscheiden of schoonmaakmiddelen van parfum. Je zou ook kunnen proberen te bepalen wanneer voedsel bedorven is.
Er zijn bepaalde dingen die u moet overwegen wanneer u een toepassing kiest. U hebt veel specimens nodig voor elke klasse die u wilt onderscheiden, om ervoor te zorgen dat het algoritme robuust wordt. Om te beginnen moet u iets kiezen dat goedkoop en overal verkrijgbaar is. Bedenk ook dat het raadzaam is normale lucht als een van de klassen te gebruiken, omdat die bijna altijd aanwezig zal zijn.
Om een robuust algoritme te maken, moet u voor elk specimen ten minste een half uur meetgegevens gebruiken. Daarom zijn specimens die een constante geur produceren een goede keuze. Zorg er ook voor dat je een breed scala aan specimens gebruikt. Als je bijvoorbeeld alleen sinaasappels, citroenen en limoenen gebruikt voor je fruitklasse, kan het zijn dat de sensor een framboos niet als fruit classificeert, omdat die te veel verschilt van de specimens die je voor de training hebt gebruikt. Hoe meer verschillende specimens worden gebruikt, hoe beter.
Als u uw keuze hebt gemaakt, is het tijd om een nieuw AI Studio project te maken. Open AI Studio en druk op de knop Maak Project ... Knop. Druk op Configureer BME Bord als u gegevens met een specifieke configuratie wilt opnemen.
2. Gegevens opnemen
Dit proces varieert, afhankelijk van of u de BME688 Breakout Raad of Bosch BME688 gassensor-ontwikkelaarkit (verder shuttle-bord). Het shuttle-bord is gemakkelijker te gebruiken en zal acht keer sneller gegevens vastleggen dan het breakout-bord, maar het is een stuk duurder. Ik zal beide methoden in de volgende secties in detail uitleggen.
Let op: De BME688 sensor heeft enige tijd nodig om zich aan te passen aan de omgeving en in te branden. Laat de sensor ten minste 24 uur draaien voordat u uw trainingsgegevens registreert.
Gegevens opnemen met de BME688 Shuttle Board
BOSCH heeft het shuttle board uitgerust met acht BME688 sensoren, waardoor het acht keer zoveel data produceert in dezelfde tijd. Alle software is al geïnstalleerd, en het is klaar om uit de doos te gaan. Kijk op deze video-handleiding van Bosch om meer te leren over het meetproces.
Als u veel specimens in één sessie opneemt, kunt u de volgorde van de specimens noteren om verwarring te voorkomen. U kunt de gegevens later altijd in AI Studio bijsnijden, dus wees niet bang om veel gegevens vast te leggen.
Gegevens opnemen met de BME688 Breakout Board
Als u de BME688 Breakout Raad Ik adviseer je nog steeds om de Bosch handleiding omdat het nuttige informatie geeft over het trainingsproces in AI Studio. Maar om de trainingsgegevens vast te leggen zijn enkele extra stappen nodig.
Wij van pi3g een python bibliotheek gemaakt voor de BME68X sensoren, die u kunt upgraden met Bosch BSEC 2.0. Het is dus handig als je wat python ervaring hebt, maar het is niet noodzakelijk.
Let op: Zie de installatie- en gebruiksinstructies rechtstreeks op onze GitHub.
Begin met het klonen van onze bme68x-python-bibliotheek. Dit kan worden gedaan door het volgende commando uit te voeren in een bash terminal.
git clone https://github.com/pi3g/bme68x-python-library.gitNu moet je de bme68x python module bouwen en installeren. De BSEC 2.0 is propriëtaire software, dus u moet versie 2.0.6.1 rechtstreeks van Bosch downloaden en akkoord gaan met hun licentie. Unzip het in de bme68x-python-library map en ga verder met deze commando's.
cd path/to/bme68x-python-library
sudo python3 setup.py installNu kunt u de bmerawdata.py script met de standaard instellingen.
cd tools/bmerawdata
python3 bmerawdata.pyHet script zal na elke meting de opgenomen gegevens weergeven. Beëindig het script en sla de gegevens op in een bestand dat compatibel is met AI Studio door te drukken op Ctrl+c.
3. Train het algoritme
Gegevens importeren
Ongeacht of u de BME688 Breakout Raad of de Bosch BME688 gassensor-ontwikkelaarkitde volgende stap is het importeren van de gegevens in AI Studio. Druk op de Gegevens importeren knop en selecteer uw .bmerawdata bestand.
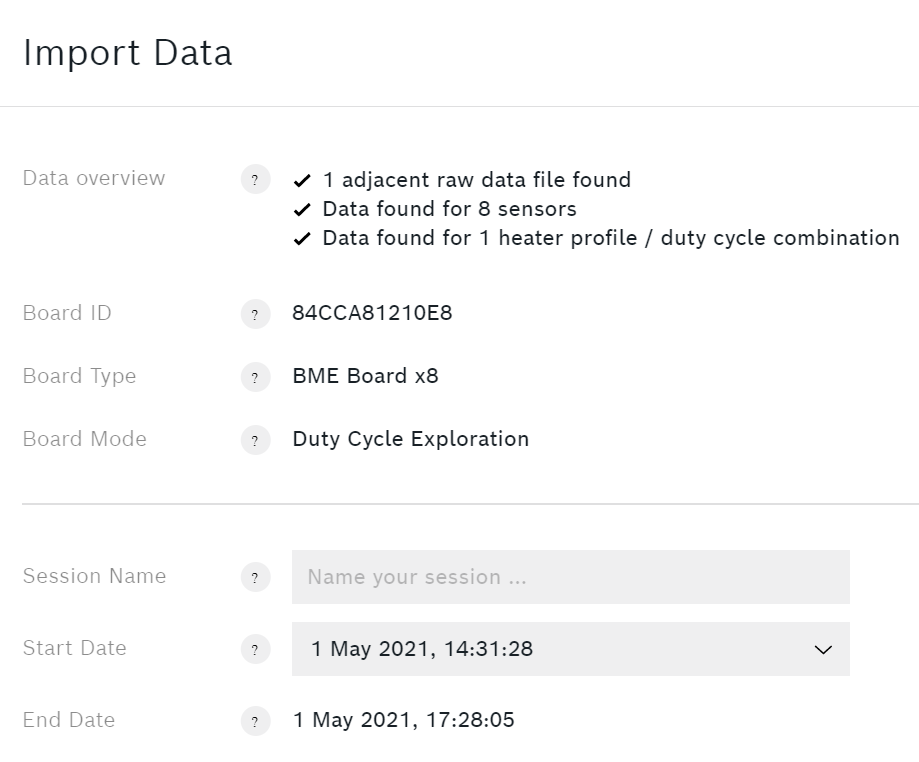
Uw sessie heeft een betekenisvolle naam nodig. Het is geschikt om een opsomming van de specimens te kiezen.
U kunt een plot van uw gegevens zien, bijvoorbeeld van het gegevenskanaal voor gas, zoals hieronder getoond.
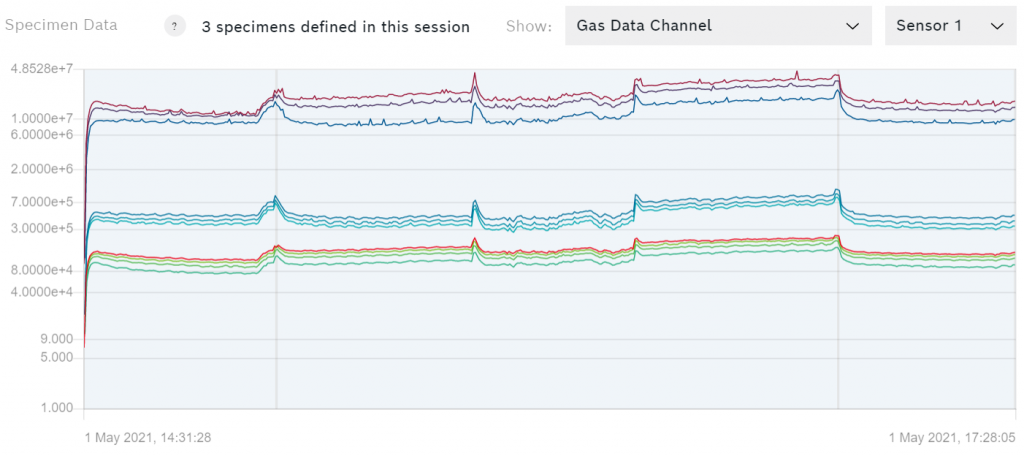
Als de gegevens afkomstig zijn van het shuttle-bord kunt u schakelen tussen de gegevens van de acht sensoren. Elk van de gekleurde lijnen vertegenwoordigt één stap van het verwarmingsprofiel dat werd gebruikt om de gegevens vast te leggen.
Let op: In de meeste gevallen moet u alleen het gas-gegevenskanaal gebruiken voor training.
Nu moeten we onze specimens van een etiket voorzien. Als u de gegevens hebt opgenomen met het shuttle-bord en de knoppen op het bord hebt gebruikt om de specimens te markeren, zult u al een sjabloon voor elk van hen kunnen zien. U kunt de preparaten ook bijsnijden en nieuwe preparaten maken (bijvoorbeeld als u meerdere preparaten hebt opgenomen met ons uitbreekbord).
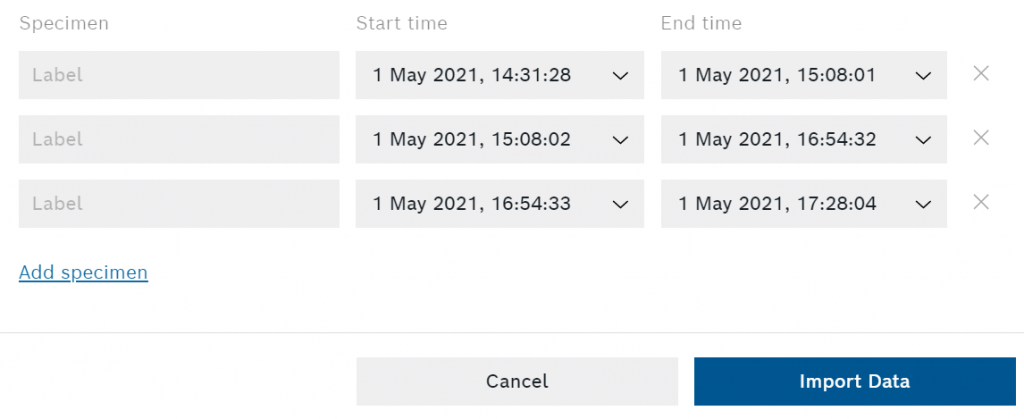
Nadat u klaar bent met het bewerken van de sessie drukt u op de Gegevens importeren knop in de rechterbenedenhoek van het dialoogvenster.
Zodra u al uw specimens hebt geïmporteerd en gelabeld, is het tijd om het algoritme te maken en te trainen.
Maak het algoritme
Selecteer Mijn algoritmen bovenaan en klik op + Nieuw algoritme . Geef je algoritme een naam die weergeeft wat het geacht wordt te doen, in mijn geval AirMeatCheese. Voeg dan de klassen toe. Ik heb mijn klassen NormalAir, Meat en Cheese genoemd. Selecteer welke exemplaren tot welke klasse behoren en kies een kleur voor elke klasse.

Om specimens toe te voegen of te verwijderen kunt u op een van de klassen klikken. Hier is een voorbeeld van wat de Vlees klasse eruit ziet.
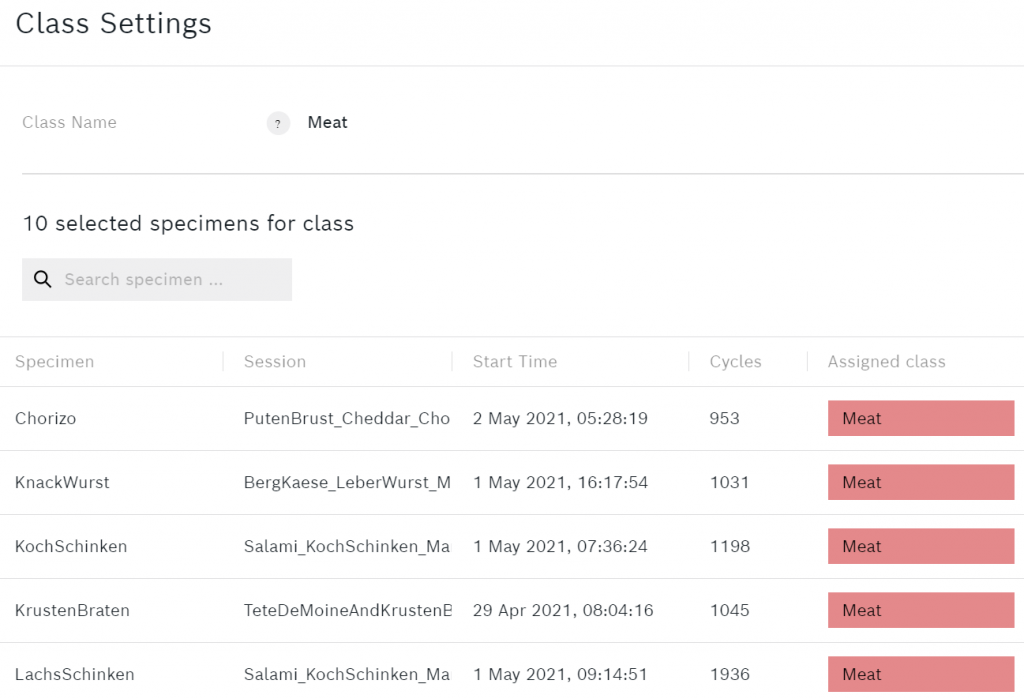
Onder de klassen ziet u enkele aanvullende gegevens over het algoritme.
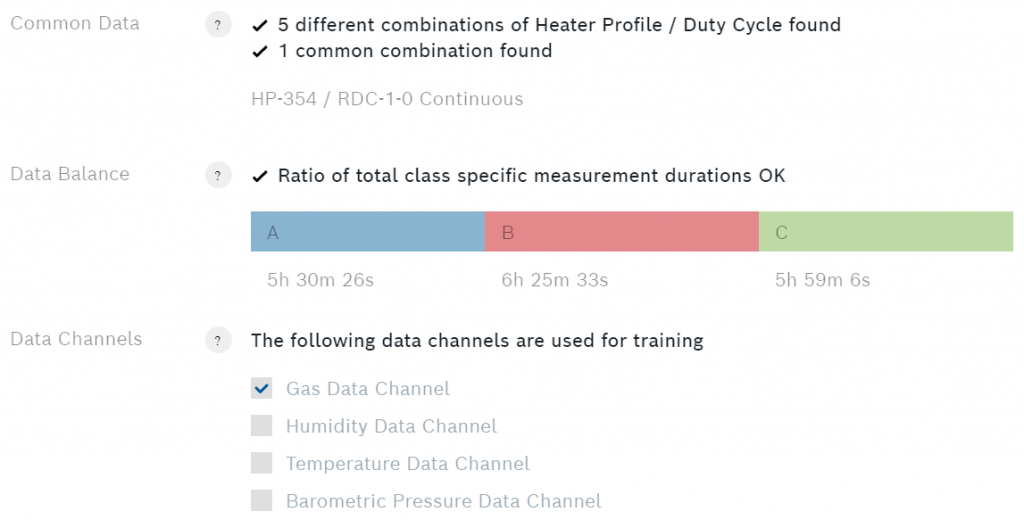
De gegevensbalans toont de totale meetduur voor elke klasse. Voor een optimale prestatie moet de meetduur van elke klasse gelijk zijn. Als de meetduur van een van de klassen veel langer is, kan het algoritme een vertekening naar die klasse vertonen. Let ook op de vraagtekenknop voor elke rubriek. Druk erop om meer gedetailleerde informatie te verkrijgen.
Let op: Raadpleeg de BME688 AI Studio Documentatie voor meer informatie.
Onder datakanalen kunt u kiezen welke van de vier sensoruitgangen u wilt gebruiken voor uw algoritme. Ik raad aan alleen het gaskanaal te gebruiken, omdat de andere kanalen meestal afhankelijk zijn van de omgeving en niet van het preparaat. Als u alles heeft ingesteld is het tijd voor training.
Opleiding en export
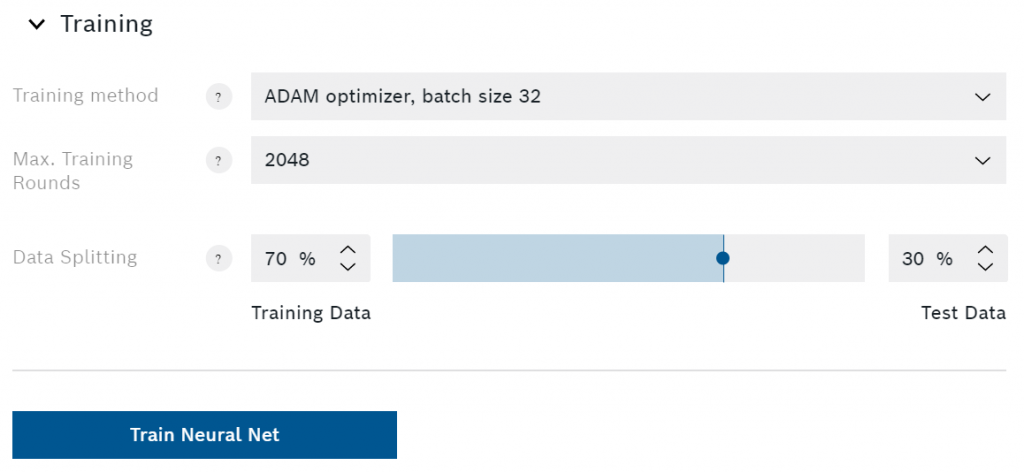
Hier kunt u de trainingsmethode, de maximale rondes en de datasplitsing kiezen. Als u nieuw bent met neurale netwerken, kunt u het beste alles op de standaard instellingen laten staan. Toch zal ik proberen elk van deze instellingen kort uit te leggen.
De enige beschikbare trainingsmethode op het moment dat ik dit schrijf is de ADAM optimizer. Dit is een specifieke manier om een minimum in de foutfunctie te vinden (minder fout betekent nauwkeurigere voorspellingen). U kunt verschillende batchgroottes selecteren om de trainingssnelheid en -stabiliteit te verbeteren.
Het verhogen van het maximum aantal trainingsrondes is een andere manier om de prestaties van het algoritme te verbeteren. Voor elke ronde (ook wel epoch genoemd) voert AI Studio de volledige reeks trainingsgegevens door het neurale netwerk. Dat betekent dat een hoger aantal maximum rondes de tijd die nodig is om het algoritme te trainen zal verhogen. In de meeste gevallen zal AI Studio detecteren of een minimum is bereikt en de training beëindigen voordat de maximale rondes zijn bereikt. Dit verkort de trainingstijd en vermijdt overfitting.
Overfitting betekent dat het neurale netwerk zich te veel heeft aangepast aan de trainingsgegevens. Als het algoritme een zeer hoge nauwkeurigheid scoort in de training, maar slecht presteert in de praktijktests, zou je de maximale trainingsrondes kunnen verlagen.
Met de instelling voor het splitsen van gegevens kunt u instellen hoeveel van de opgenomen gegevens worden gebruikt voor training en hoeveel voor testen. U moet vermijden meer dan een derde van de gegevens te gebruiken voor testen. Zoals de naam al aangeeft, zal het algoritme alleen de trainingsgegevens gebruiken om te trainen. Nadat de training is voltooid, zal AI Studio het algoritme evalueren met behulp van de testgegevens, die het nog nooit heeft gezien.
Druk op Train Neuraal Net om de training te starten. U ziet de geschatte resterende trainingstijd en een lijngrafiek van de nauwkeurigheid en het verlies.
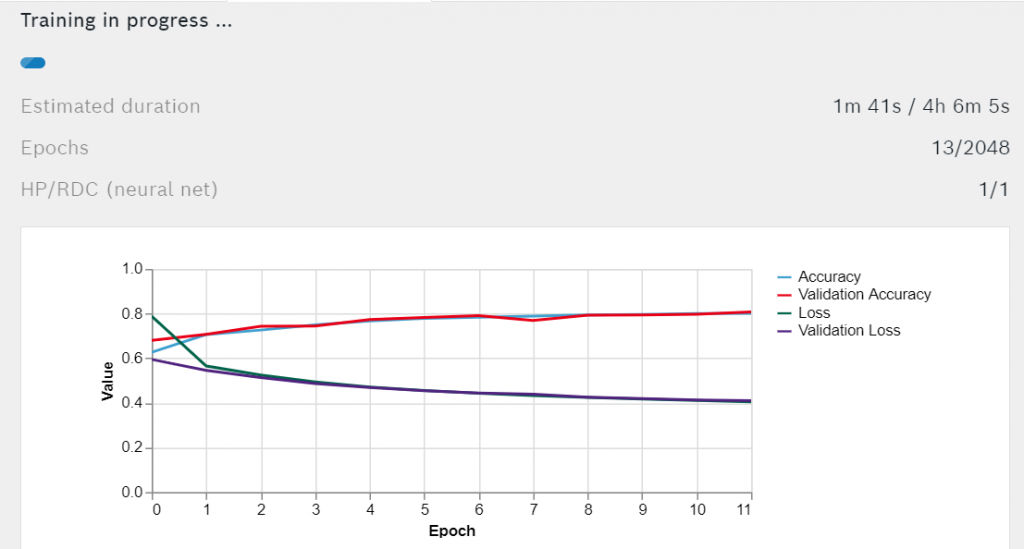
Met elke tijdseenheid moeten de nauwkeurigheid en de validatie-nauwkeurigheid verbeteren, terwijl het verlies en het validatieverlies moeten afnemen. Wacht tot de training is voltooid.
Als de training klaar is, controleer dan de verwarringsmatrix. Deze bevat belangrijke informatie over de trainingsresultaten. De meest interessante statistiek is de nauwkeurigheid, maar als de trainingsgegevens ongelijk verdeeld zijn, is de F1 score wellicht een betere maatstaf.
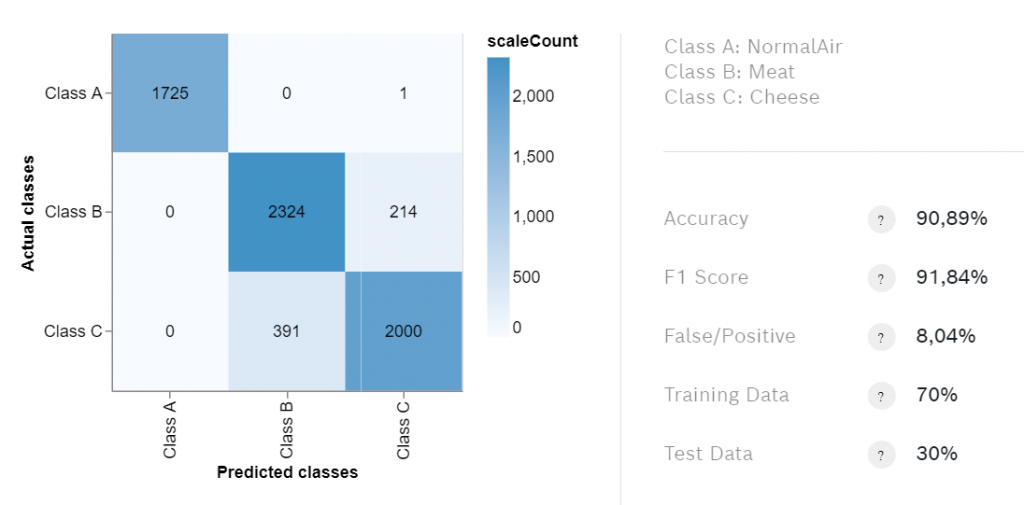
U zult zelden een nauwkeurigheid van meer dan 90% bereiken, dus als de nauwkeurigheid boven 80% ligt, moet u het algoritme exporteren om het te testen. We zullen geuren detecteren met behulp van onze PiCockpit web-interface. Zorg ervoor dat u het algoritme voor BSEC versie 2.0.6.1 exporteert, aangezien PiCockpit ondersteunt tot nu toe alleen deze versie.
Let op: In de meeste gevallen zal de opleiding voltooid zijn voordat de geschatte duur is bereikt.
4. Detecteer geuren
Om geuren te detecteren installeer je gewoon de PiCockpit client en verbind deze met uw account. Indien u niet beschikt over PiCockpit maar je hoeft je alleen maar gratis te registreren en de daar gegeven instructies te volgen. Met onze Digitale Neus App kunt u uw getrainde algoritme uploaden en live voorspellingen bekijken via de webinterface. Bekijk de Digitale Neushulp voor een volledige uitleg over hoe de app te gebruiken.
Een andere manier om geuren op te sporen is met behulp van onze BME68X Python uitbreiding. Dit vereist wat python codering maar biedt meer controle en stelt u in staat uw eigen toepassingen te maken met uw algoritme. Raadpleeg de README.md, de Documentatie.md en de voorbeelden map om te leren hoe u de extensie installeert en gebruikt.
Dus daar heb je het. U zou nu in staat moeten zijn om data op te nemen, uw algoritme te trainen en geuren te detecteren. Laat het me weten als je deze gids nuttig vond of als je problemen hebt ondervonden bij het volgen van deze gids.
Neem contact met me op via [email protected]
Bij mij werkt het trainen van het algoritme niet. In plaats daarvan geeft de software de foutmelding "Algorithm could not be trained. Ofwel training data ofwel test data lijkt te ontbreken.". Ik heb echter voor elk van mijn klassen ongeveer een uur aan data verzameld met behulp van de BME688 Breakout Board. Hebt u enig idee wat ik verkeerd zou kunnen doen?
Dit klinkt alsof het .bmerawdata bestand corrupt kan zijn. Je zou kunnen proberen een kijkje te nemen in het bestand, om te zien of er slechte waarden in staan. Het is in json formaat
Heb je hier een oplossing voor gevonden?
Hoi Nathan.
Ik heb ook net je code uitgeprobeerd en ik krijg dezelfde fout bij het maken van een algoritme.
" Ofwel training data ofwel test data lijkt te ontbreken."
Is er misschien een probleem in je code?
Hallo Thomas.
Ik heb de fout nog niet kunnen herstellen.
Welke versie van AI Studio dp je gebruikt? Het script is getest met AI Studio versie 1.6.0
Hoi Nathan.
Ik heb de nieuwste versie gebruikt (1.6.0) en ik heb je er een mail over gestuurd, dus wil je dat ik je de voorbeeldbestanden stuur?
Heb al veel testen geprobeerd maar steeds dezelfde fout 🙁
Ja, ik gebruik ook 1.6.0. Kijk naar deze bestanden van de dataverzameling. Een is rook, de andere is normale lucht. https://we.tl/t-PwfkYXjnGP
[...] op, zoals een temperatuur- en vochtigheidssensor of misschien een luchtkwaliteitsproject met een DHT22 of BME688, of een helderheidssensor met een licht [...]
[Leer je BME688 hoe je moet ruiken [...].